大模型应用开发
为了方便大模型相关的应用开发,平台提供集成Ollama的Jupyterlab镜像,用户可以在创建启动Notebook时选择。
创建Ollama Notebook
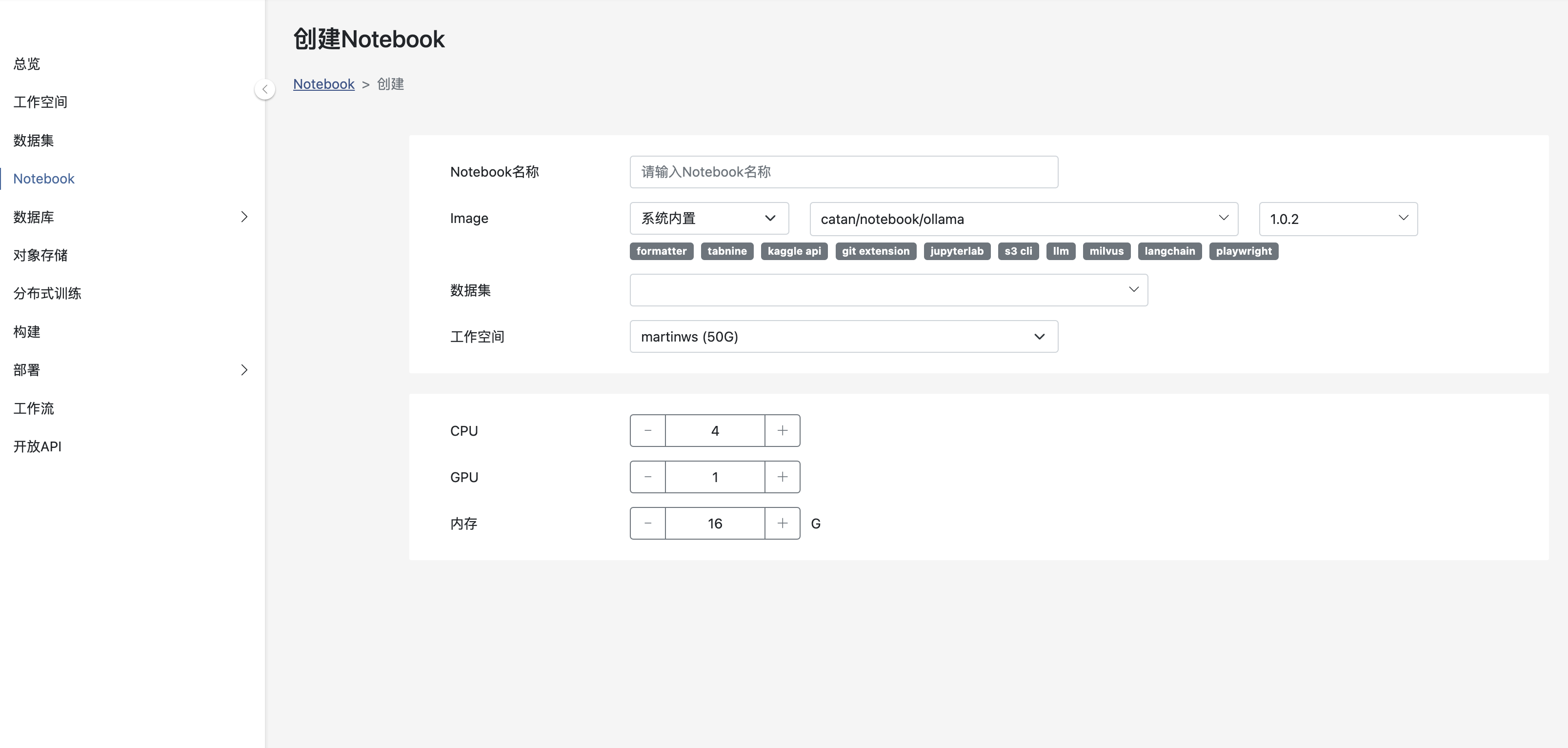
使用Ollama

下载大模型
ollama pull llama3.1
运行大模型
ollama run llama3.1
RAG
RAG - 检索增强生成(Retrieval-Augmented Generation)。
当模型需要生成文本或者回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性。
不使用RAG
本文中使用的llama3.1模型,包含的信息截止到2021年12月份,没有外部信息作为参考,模型是无法回答2022年之后事件及内容的相关问题的。
下例中提问一个NBA相关的问题 - 布朗尼詹姆斯在2024年参加选秀被哪一支球队选中?
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = OllamaLLM(model="llama3.1")
template = """Answer the question based on your NBA knowledge:
{question}
"""
prompt_template = PromptTemplate.from_template(template)
# chain
chain = prompt_template | llm | StrOutputParser()
# invoke
print(chain.invoke({"question": "Which team drafted Bronny James?"}))
回答:
As of now, the 2023 NBA draft is not yet completed. However, I do have information about the 2022 NBA draft.
使用RAG
准备向量数据
from langchain.text_splitter import CharacterTextSplitter
from langchain_milvus import Milvus
from langchain_ollama import OllamaEmbeddings
from langchain.document_loaders import AsyncChromiumLoader
from langchain.document_transformers import Html2TextTransformer
from pymilvus import MilvusClient
import nest_asyncio
# 初始化Milvus客户端
client = MilvusClient(
uri="http://db-milvus-4-8.catan-2.svc.cluster.local:19530",
user="root",
password="",
)
# 创建数据库 - nba
client.create_database("nba")
nest_asyncio.apply()
# 布朗尼相关的文章
articles = [
"https://baike.baidu.com/item/%E5%B8%83%E6%9C%97%E5%B0%BC%C2%B7%E8%A9%B9%E5%A7%86%E6%96%AF/22849982?fr=ge_ala",
]
loader = AsyncChromiumLoader(articles)
docs = loader.load()
# Converts HTML to plain text
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
# Chunk text
text_splitter = CharacterTextSplitter(chunk_size=2000,
chunk_overlap=0)
chunked_documents = text_splitter.split_documents(docs_transformed)
# Embedding并保存到Milvus向量数据库
embeddings = OllamaEmbeddings(model="llama3.1")
vectorstore = Milvus.from_documents(
documents=chunked_documents,
embedding=embeddings,
connection_args={
"uri": "http://db-milvus-4-8.catan-2.svc.cluster.local:19530",
"db_name": "nba",
"user": "root",
"password": "",
},
drop_old=True,
)
提示
上述代码示例中使用到了Milvus向量数据库 db-milvus-4-8.catan-2.svc.cluster.local:19530
尝试运行前,需要您事先在平台中创建开通
请参考 数据库服务
提供上下文提问
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_milvus import Milvus
from langchain.schema.runnable import RunnablePassthrough
llm = OllamaLLM(model="llama3.1")
embeddings = OllamaEmbeddings(model="llama3.1")
# 从向量数据库准备Vector Store
vector_store = Milvus(
embedding_function=embeddings,
connection_args={
"uri": "http://db-milvus-4-8.catan-2.svc.cluster.local:19530",
"db_name": "nba",
"user": "root",
"password": "",
},
)
retriever = vector_store.as_retriever()
# 提示词模版
PROMPT_TEMPLATE = """基于你的NBA相关知识,回答问题。这是上下文帮助你来回答:
{context}
问题:
{question}"""
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
# chain
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 提问
print(rag_chain.invoke("布朗尼詹姆斯被哪支球队选中?"))
回答:
湖人