数据集
数据集,顾名思义:数据的集合,AI模型训练过程中需要使用的数据。
您可以在平台上创建修改数据集,对数据集的内容进行上传,查看,删除等。
创建一个数据集
在 https://portal.ailines.cn 中,选择菜单数据集,点击 创建 按钮,如图所示:
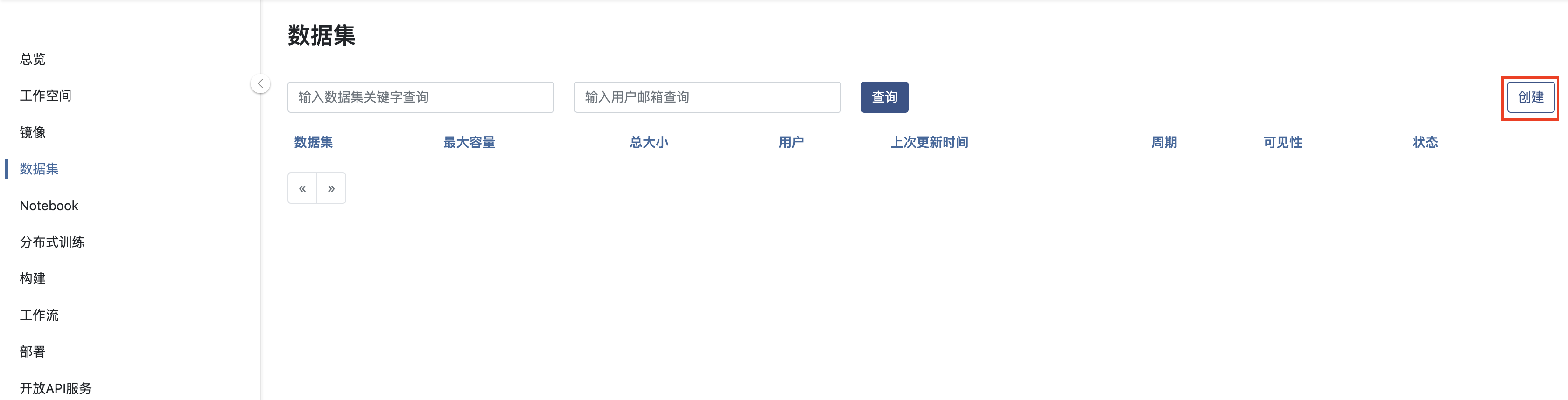
输入名称,选择可见性及规格时长,开通创建数据集:
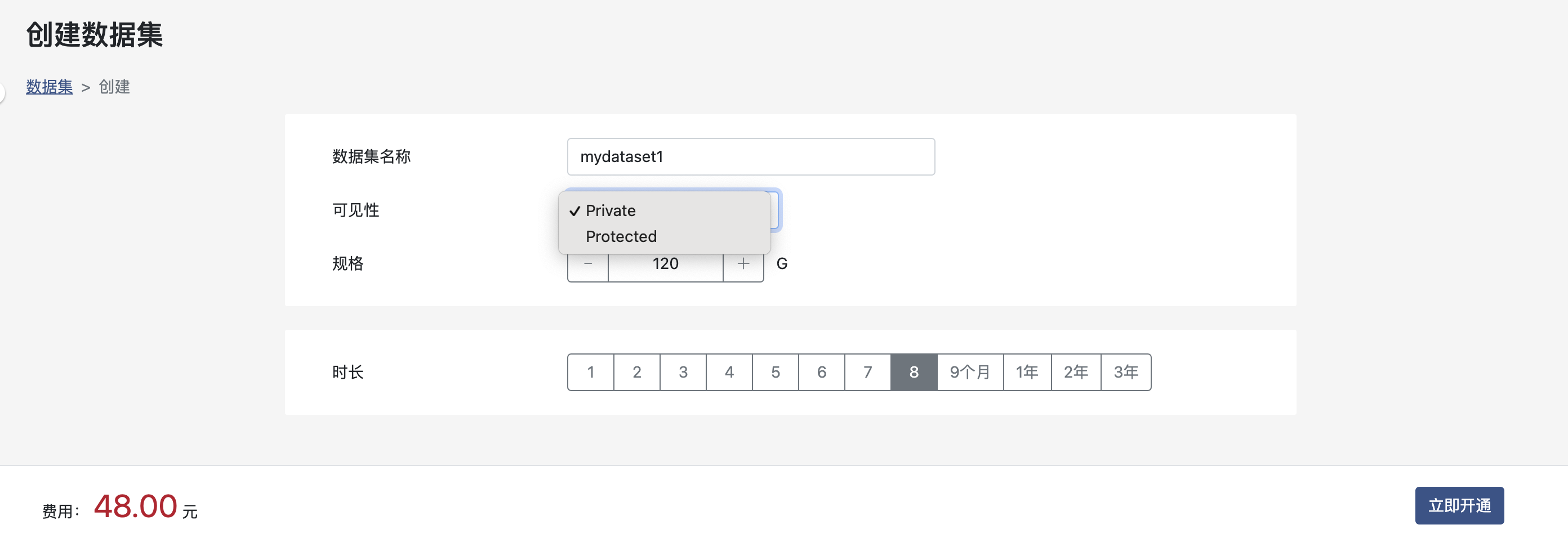
提示
数据集可见性目前有两种,用户私有(Private)和租户内共享(Protected)
编辑数据集的内容
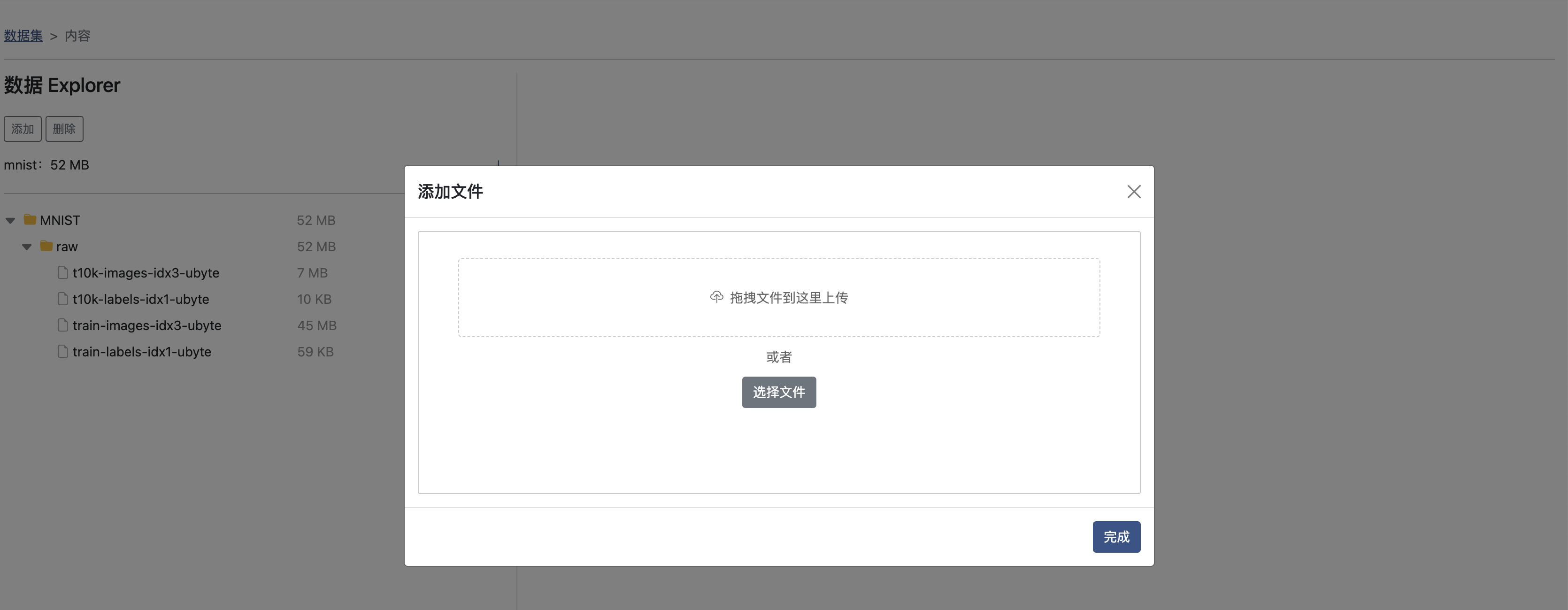
数据集列表页中点击 修改内容,进入数据集内容编辑页面,在此页面中,点击 添加 按钮。
您可以在拖拽文件夹到图中虚线区域,并完成上传:
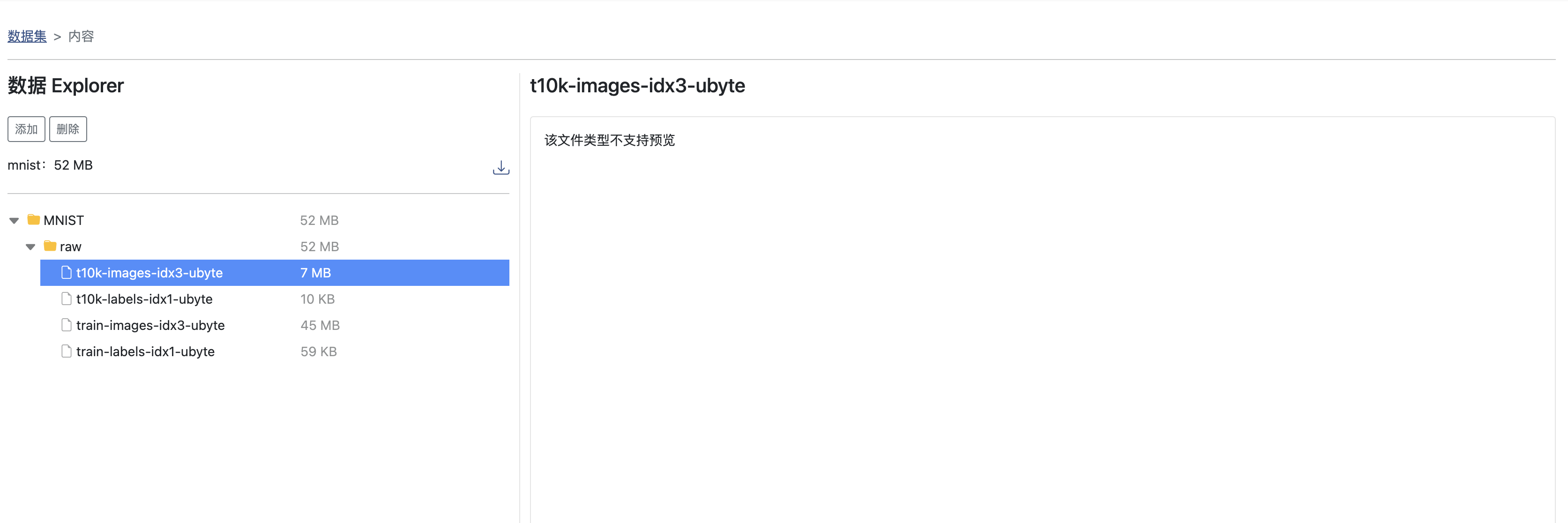
数据集所有文件按照文件夹结构展示在左侧,点击文件会在右侧展示文件内容,并可以选择某一文件或文件夹进行删除:
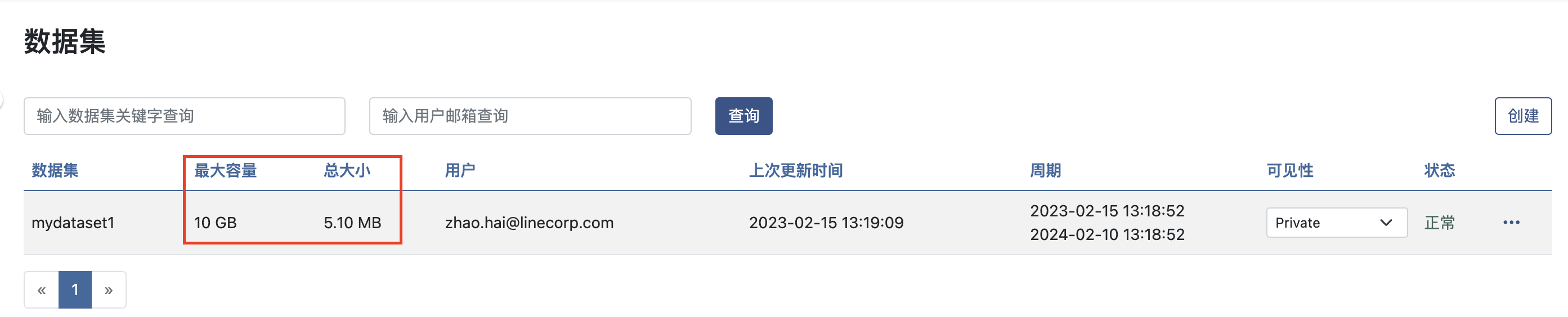
数据集的容量及大小
您可以在数据集列表页中查看到数据集的容量及目前总大小,当总大小达到容量上限,数据集编辑时将无法写入,不会影响内容的读取。
存储Pytorch公共数据集
当您存储Pytorch公共数据集时,需要注意的是,数据集的根路径必须满足要求,比如像下面例子一样,使用Pytorch的MNIST数据集时,数据集的根路径下必须存在MNIST/raw/train-images-idx3-ubyte和MNIST/raw/t10k-images-idx3-ubyte。
load MNIST dataset
train_set = MNIST(
root=data_root,
download=False,
train=True,
transform=torchvision.transforms.Compose([ToNumpy(), torchvision.transforms.ToTensor()])
)
所以为了方便的使用Pytorch公共数据集,您可以直接使用像MNIST作为AILines数据集名称,之后在使用AILines ML相关服务时,可以通过我们提供的环境变量来拼接数据集根路径,避免硬编码去拼接路径。
load MNIST dataset
# $DATASETS_PATH - AILines Dataset根目录,只读
# $DATASETS - Dataset名称列表,多个以逗号分隔
# 例如DATASETS_PATH为: /datasets
datasets_path = os.getenv("DATASETS_PATH")
def get_datasets():
# 例如DATASETS为: MNIST
datasets = os.getenv("DATASETS", "")
return datasets.split(",")
def get_dataset():
datasets = get_datasets()
if len(datasets) > 0:
return datasets[0]
return ""
# 拼接之后为: /datasets/MNIST
data_root = "{}/{}".format(datasets_path, get_dataset())
train_set = MNIST(
root=data_root,
download=False,
train=True,
transform=torchvision.transforms.Compose([ToNumpy(), torchvision.transforms.ToTensor()])
)
提示
数据集名称在一个租户下是唯一的,所以当您需要存储Pytorch公共数据集时,为了更方便地使用,对于同一个数据集,可以按照上面例子创建存储一次,然后在租户内共享使用。当然您也可以按照您理想中方式随意创建和组织数据集的目录结构,然后在编码的时候拼接上正确的路径。