Notebook
Notebook即Jupyter Notebook,在AILines系统中指的是Juypter Notebook的运行环境。
目前系统中默认提供的是Jupyterlab集成环境,方便在线开发运行等工作。
创建启动Notebook运行环境
在 https://portal.ailines.cn 中,选择菜单Notebook,点击 创建 按钮,如图所示:
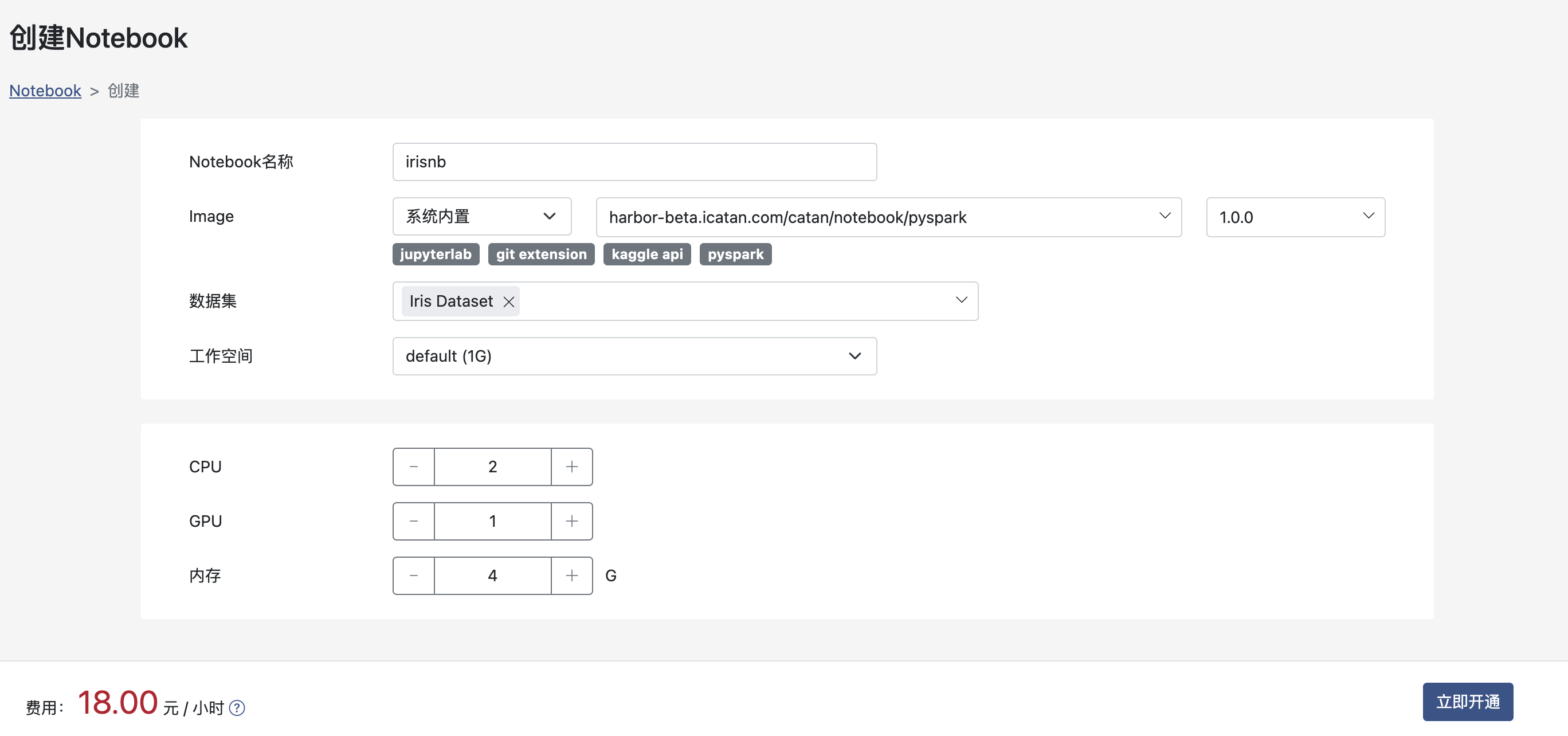
输入名称,选择镜像及其版本,选择数据集,工作空间和运行环境的配置(CPU,GPU,内存),开通启动Notebook运行环境:
点击 日志 按钮,可以查看Notebook启动日志:

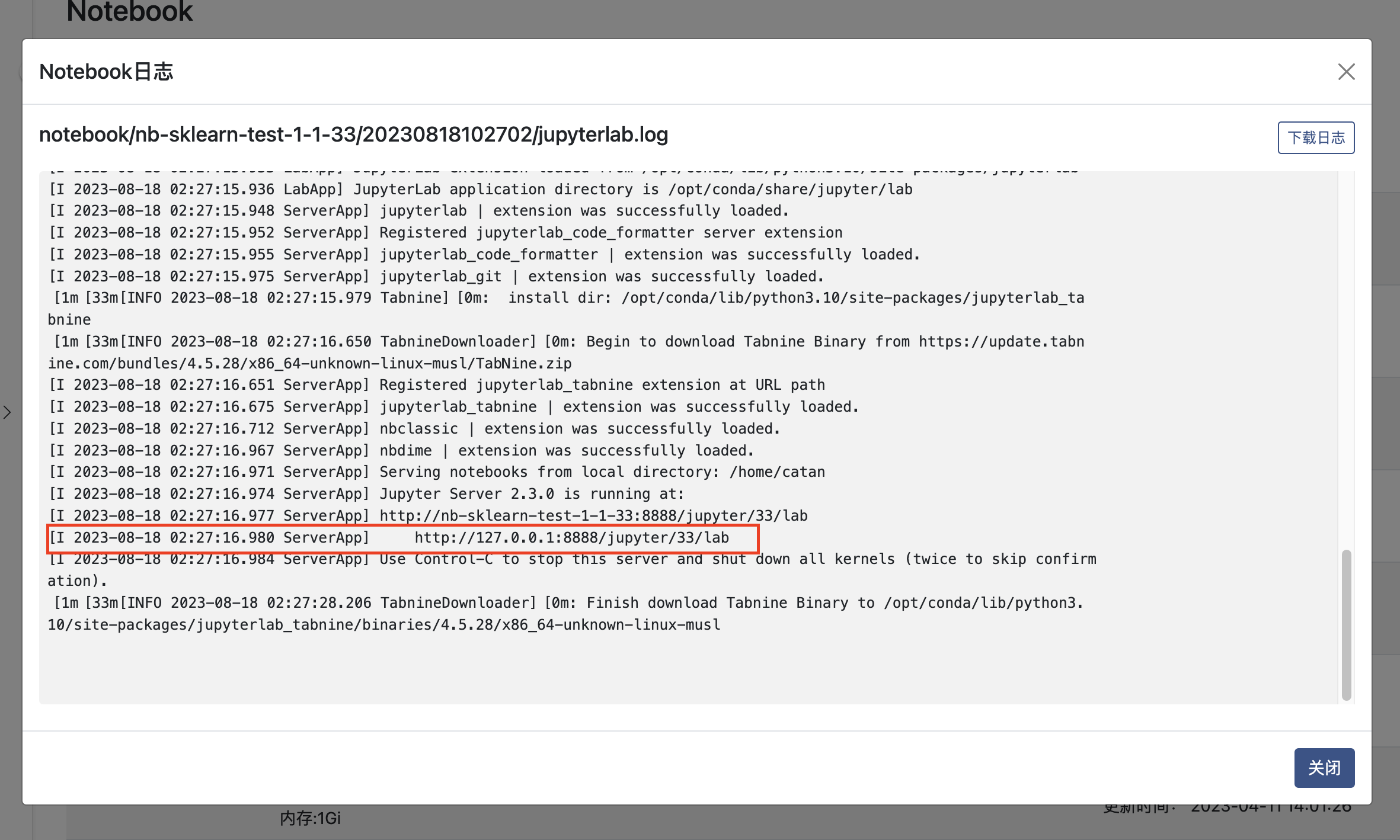
当看到如下日志,Notebook已经启动成功:
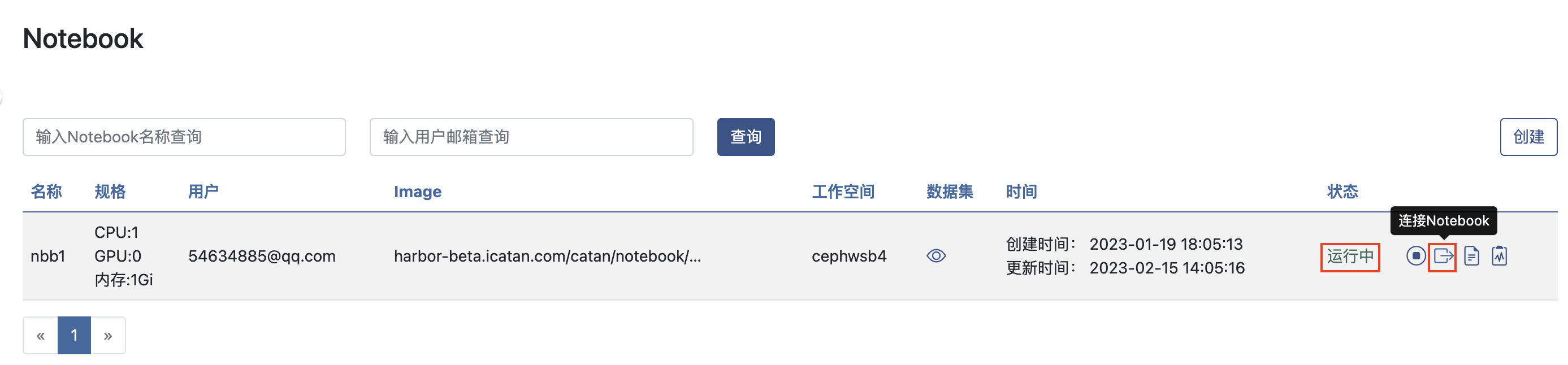
当Notebook的状态变成 运行中, 点击 连接Notebook 按钮:
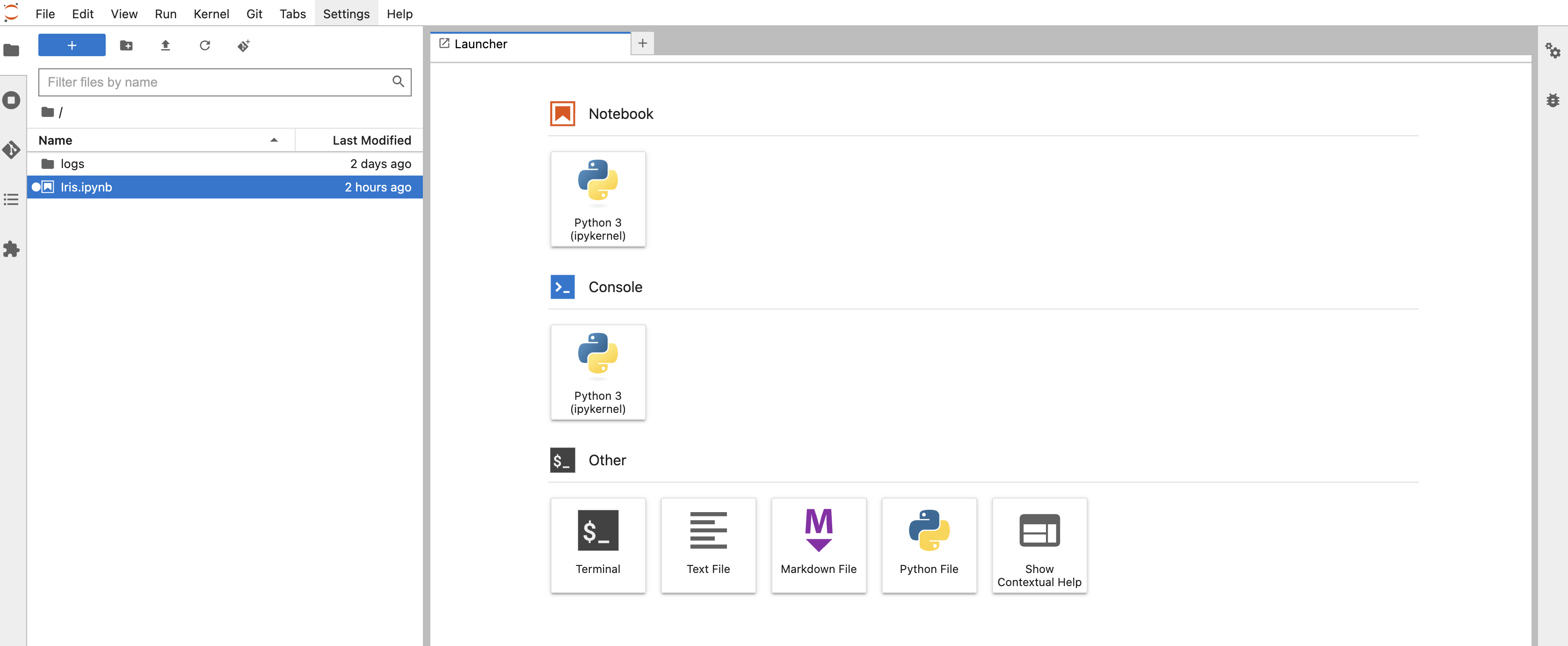
您将会看到Jupyterlab的运行环境:
提示
当您看到如上页面,您的Notebook启动成功了。
如果您是第一次启动,可能会出现502页面,这时请稍等一会或者查看启动日志,等待所有服务准备就绪,刷新页面即可。
使用Notebook
这里以训练及验证iris分类模型为例,演示如何使用Jupyter Notebook。
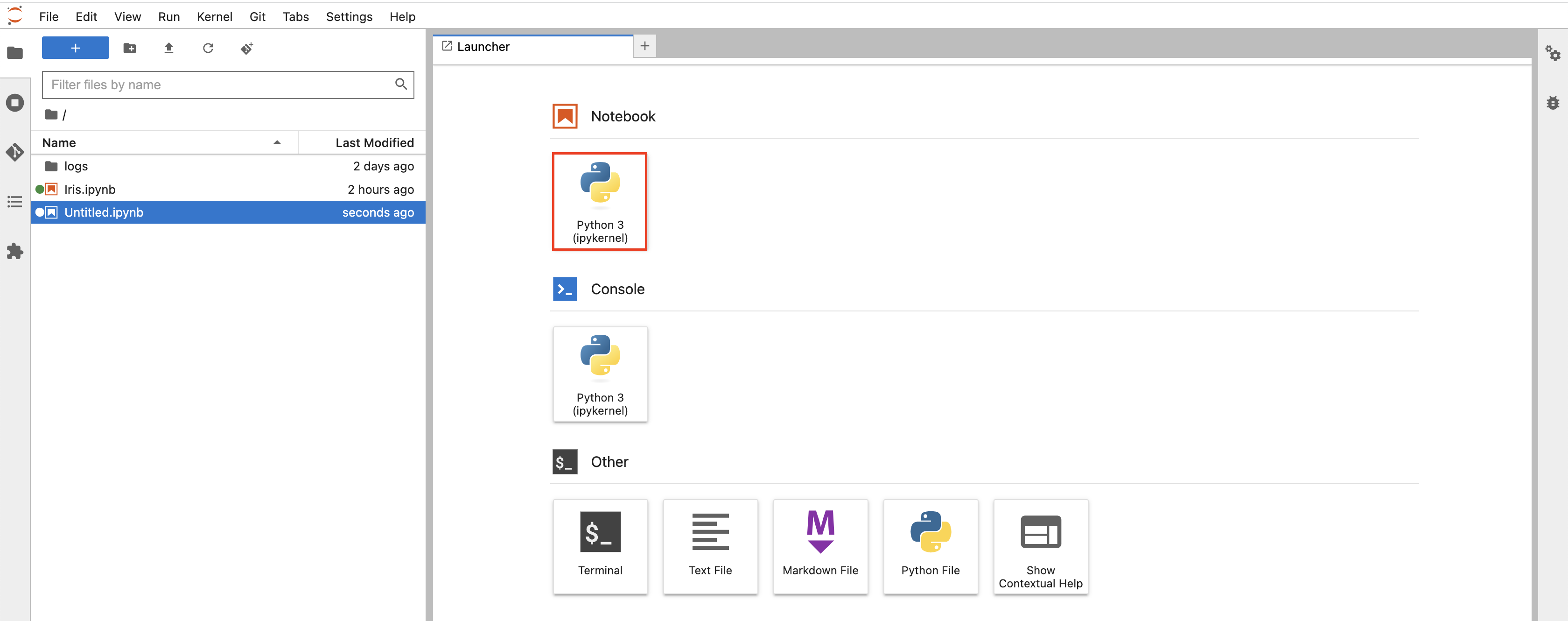
创建一个Notebook文件(.ipynb)
在 Launcher 页面中点击 Notebook 下 Python 3(ipykernel) ,保存为Iris.ipynb:
依次添加单元格
点击控制条中的加号,添加单元格:

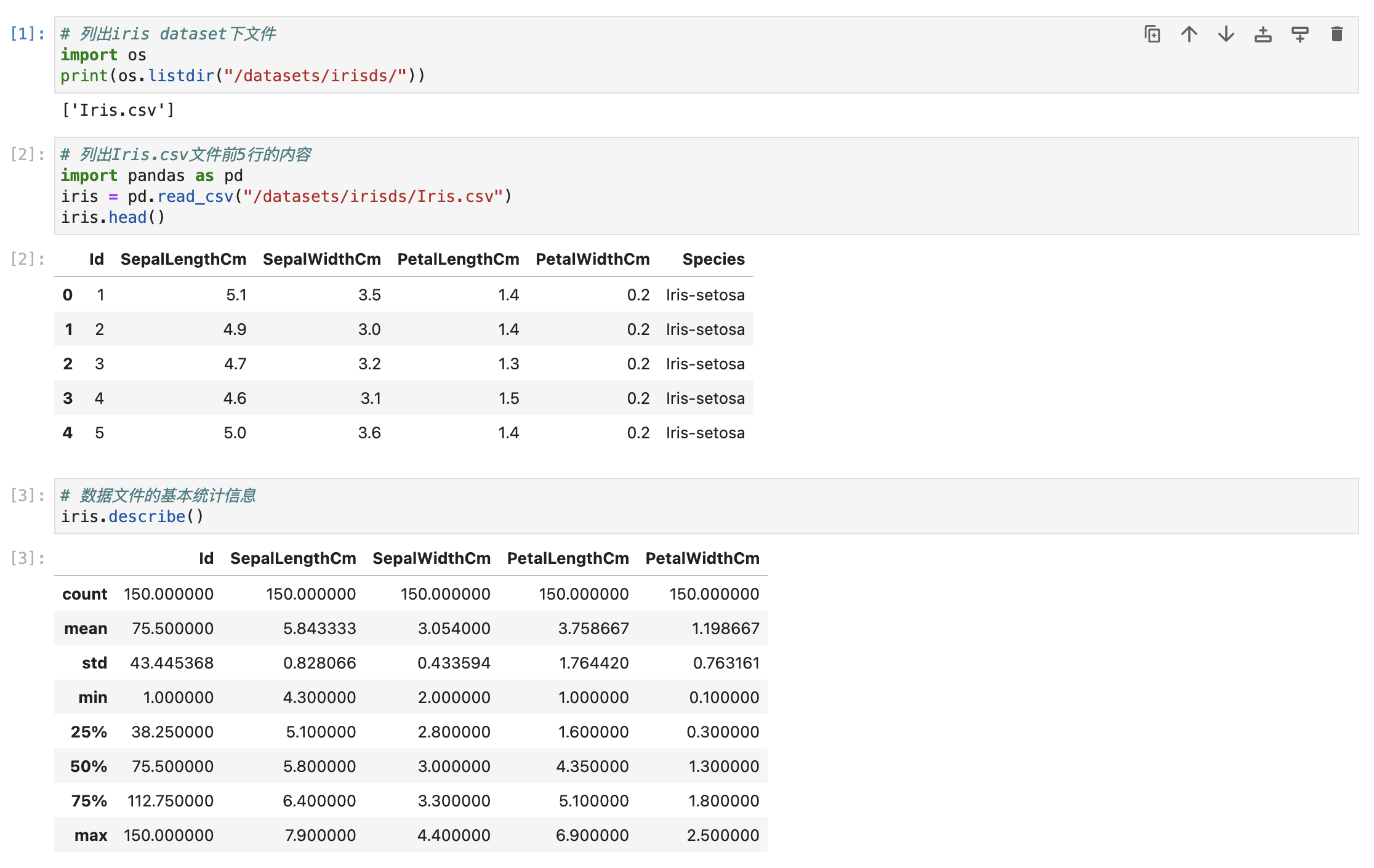
列出iris dataset下文件
import os
print(os.listdir("/datasets/irisds/"))
列出Iris.csv文件前5行的内容
import pandas as pd
iris = pd.read_csv("/datasets/irisds/Iris.csv")
iris.head()
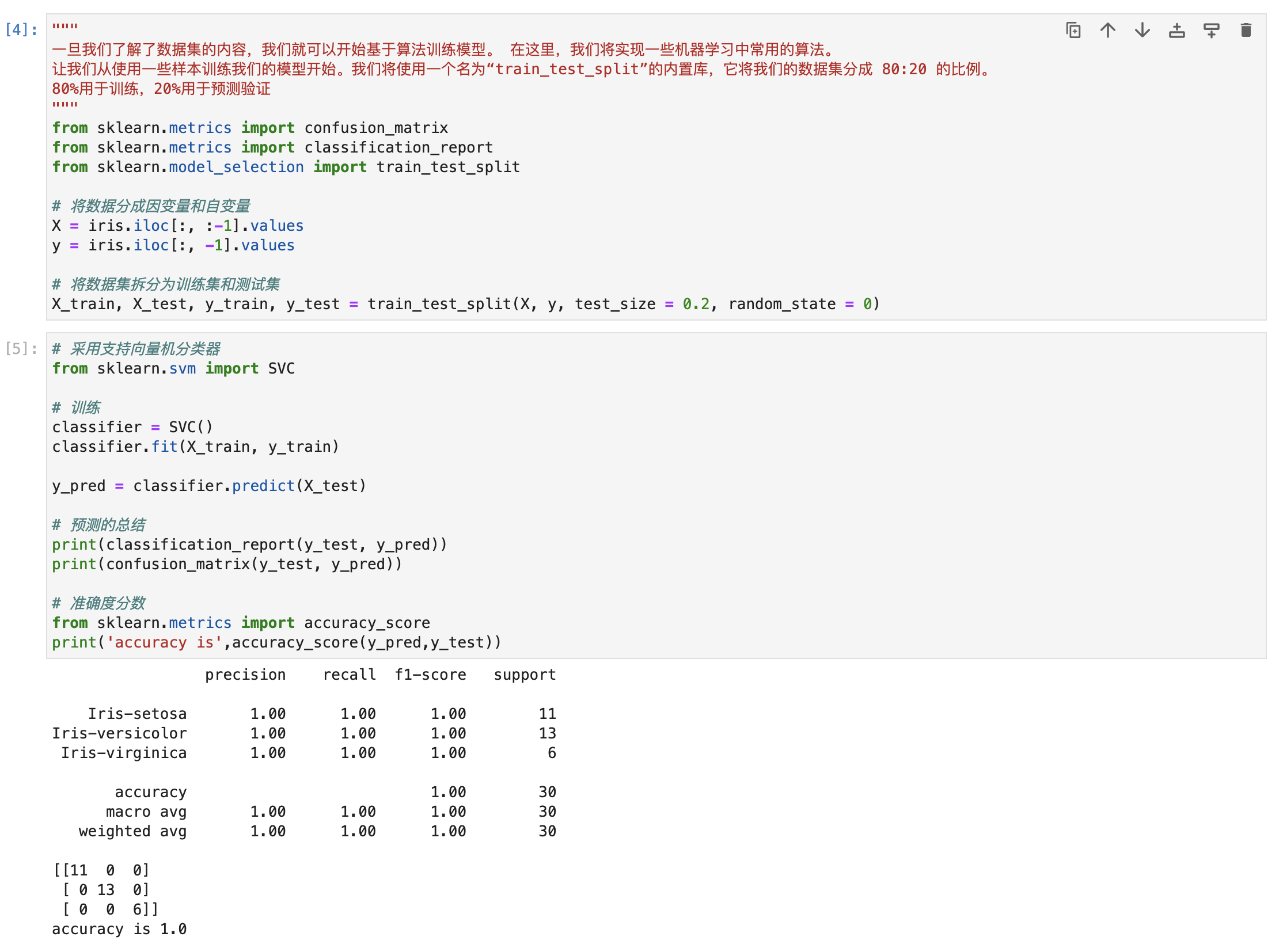
拆分数据集
"""
一旦我们了解了数据集的内容,我们就可以开始基于算法训练模型。 在这里,我们将实现一些机器学习中常用的算法。
让我们从使用一些样本训练我们的模型开始。我们将使用一个名为“train_test_split”的内置库,它将我们的数据集分成 80:20 的比例。
80%用于训练,20%用于预测验证
"""
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
# 将数据分成因变量和自变量
X = iris.iloc[:, :-1].values
y = iris.iloc[:, -1].values
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
训练及预测
# 采用支持向量机分类器
from sklearn.svm import SVC
# 训练
classifier = SVC()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# 预测的总结
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# 准确度评分
from sklearn.metrics import accuracy_score
print('accuracy is',accuracy_score(y_pred,y_test))
运行所有单元格
点击 运行所有单元格 按钮,运行并查看结果:

全部结果如下: