工作流
工作流: 可以编排一系列的步骤,然后让它们按照一定的顺序和依赖关系运行;如训练 -> 构建 -> 部署。
创建工作流
在 https://portal.ailines.cn 中,选择菜单工作流,点击 创建 按钮,如图所示:
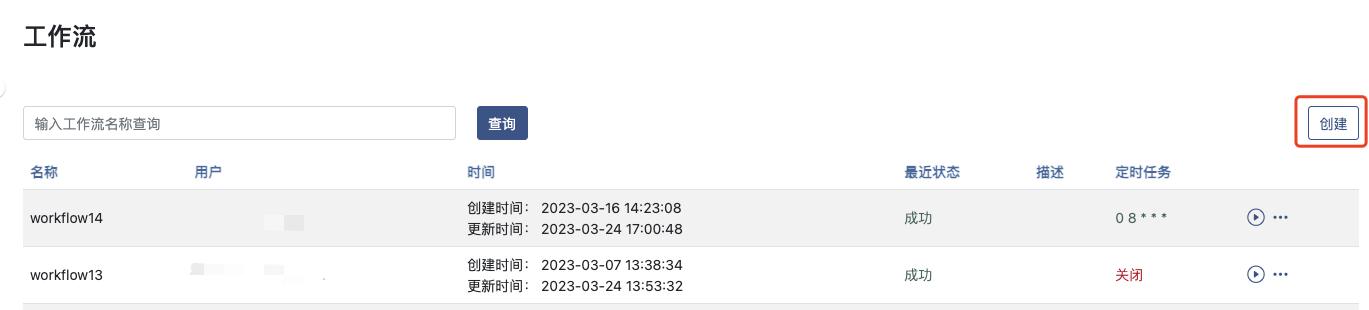
填写工作流基本信息,并进入 下一步
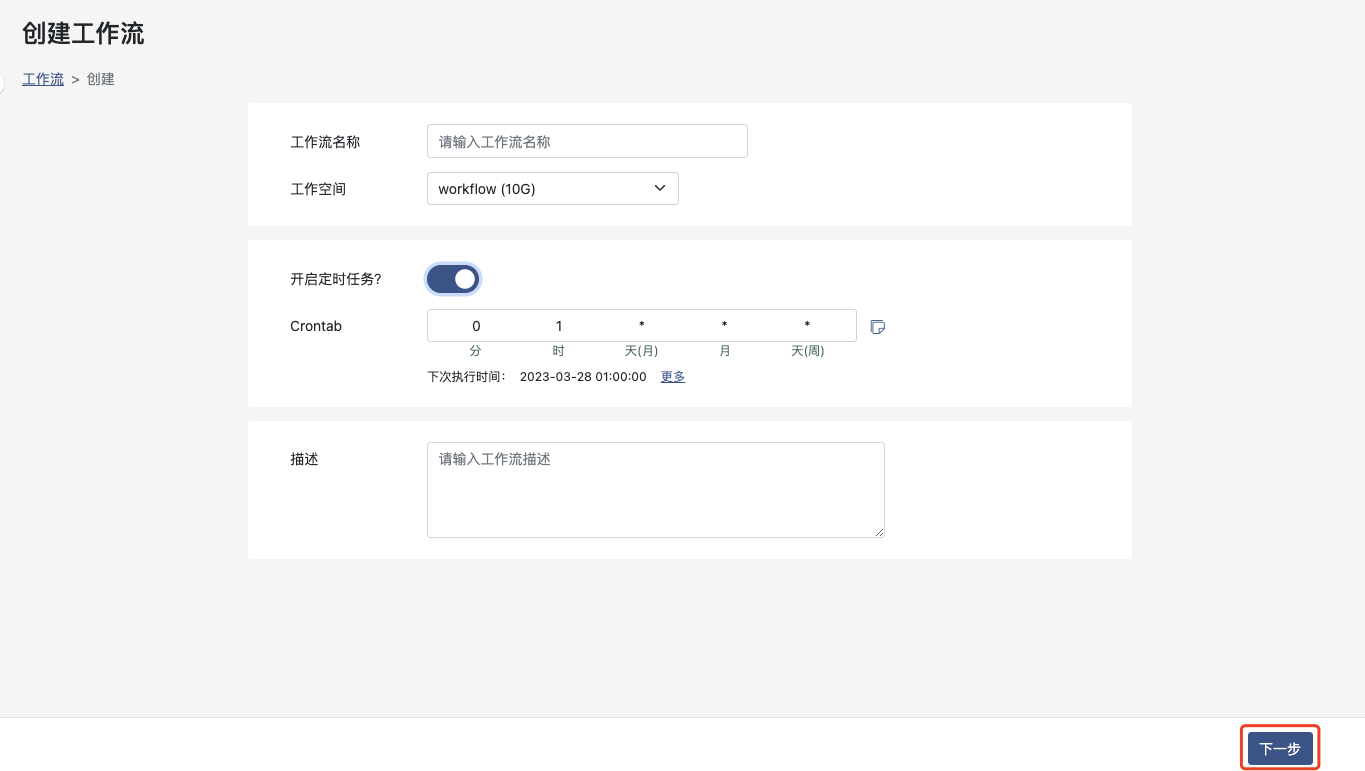
工作流名称:工作流名称,用于便于于其他工作流区分
工作空间:工作流运行中需要使用的工作空间,用于工作步骤中存储读取数据等
开启定时任务?:选择是否需要开始定时执行工作流
Crontab:定时执行表达式,可根据提醒设置定时执行规则
描述:对工作流的描述,用于记录区分工作流
设置步骤和相关属性并 点击右上按钮 保存工作流
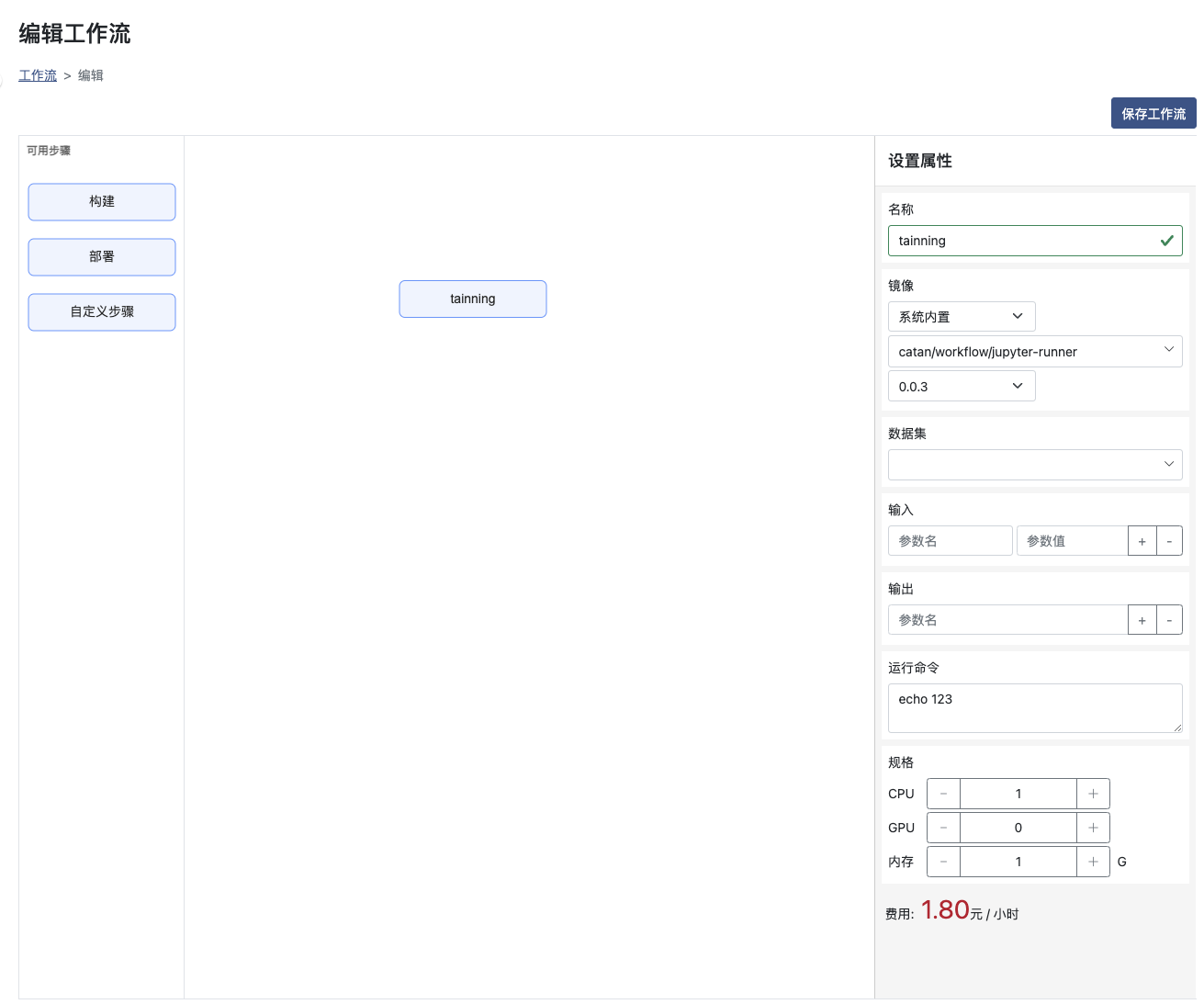
名称:需要唯一,且是以字母开头的数字字母组合
镜像:可选择内置或者用户指定仓库里的镜像
数据集:为选填项,也可以选择多个数据集
CPU GPU 内存:选择步骤运行所需要的资源
输入:运行所需要的输入参数,可在命令行中使用{{inputs.parameters.参数名}}格式读取,也可以通过选择提示的值来使用前置步骤的输出作为输入参数
输出:输出结果以便接下来的步骤使用,将运行结果写入到临时文件中(临时文件完整路径可通过环境变量 OUTPUTPARAM输出参数名 获取),并作为输出参数
运行命令:对应需要运行的命令,如运行shell脚本或者python文件等
面板收起时,会自动保存步骤属性
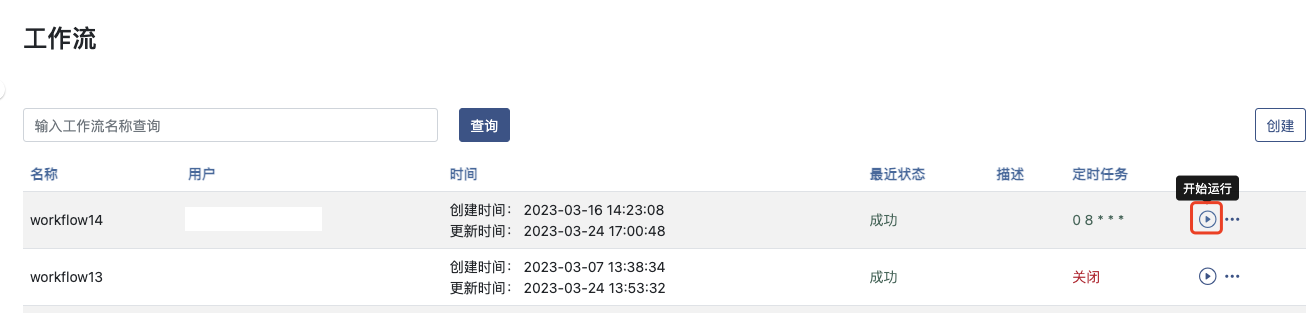
运行工作流
点击列表页的 运行 可以直接运行工作流
编辑工作流
点击 编辑 按钮
修改定时任务
点击 修改定时任务 按钮,可以关闭或者修改工作流的定时配置
查看运行历史
点击 运行历史 按钮
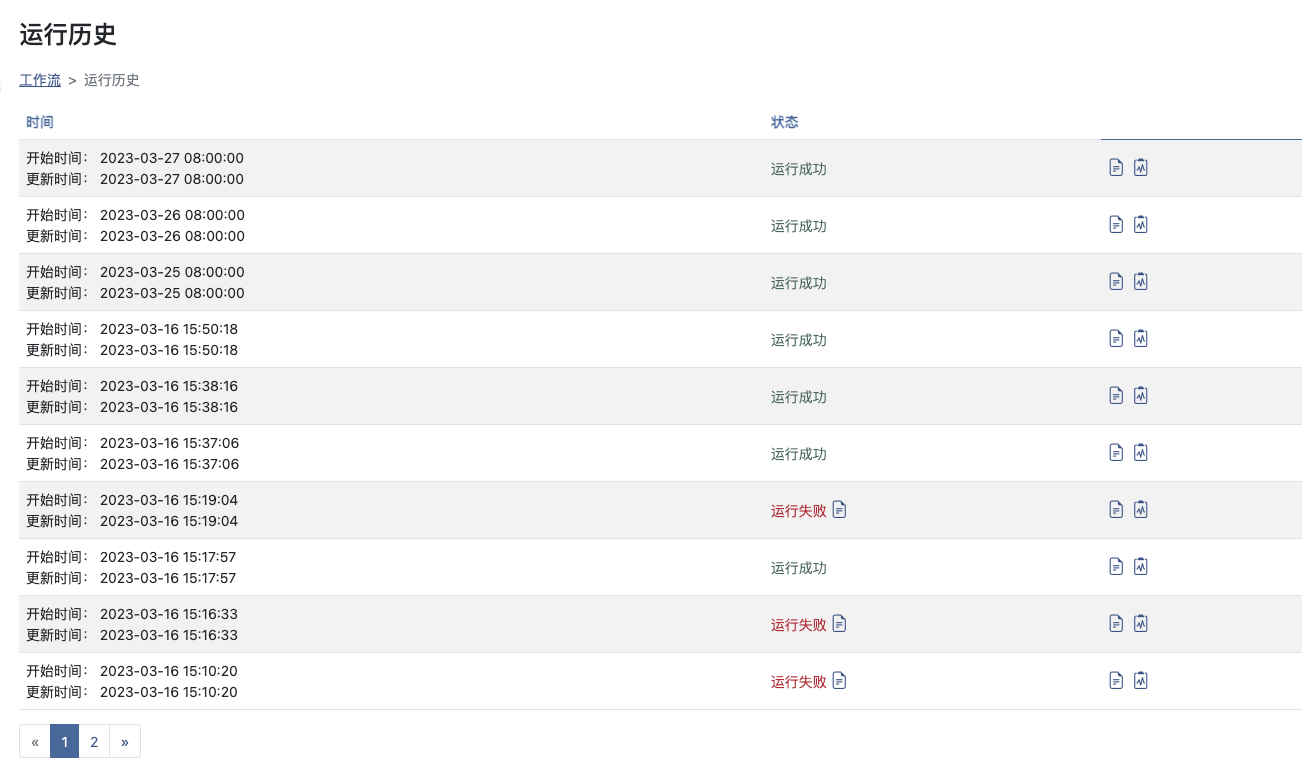
运行历史界面可以查看此工作流的所有历史
查看日志
在工作流列表页,点击 最近日志 按钮,查看最近运行记录的日志
或者在运行历史页,点击 日志,查看历史对应的日志
查看监控
在工作流列表页,点击 监控 按钮,查看最近运行记录的监控

或者在运行历史页,点击 监控,查看历史对应的监控
删除工作流
在工作流列表页,点击 删除 按钮
内置步骤的使用
构建
使用内置的 构建 步骤
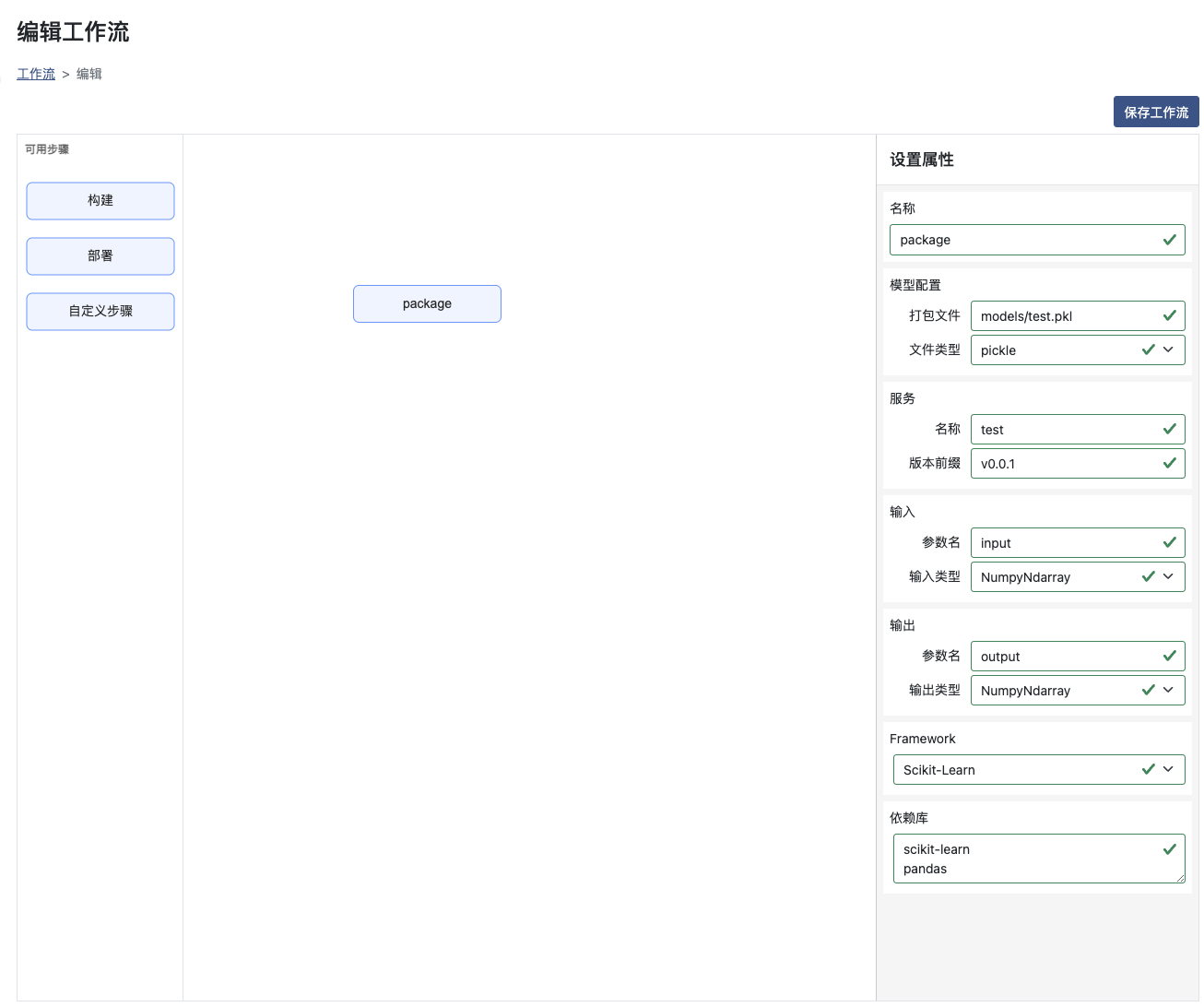
名称:需要唯一,且是以字母开头的数字字母组合
模型配置-打包文件:模型文件的完整路径,需要是pickle格式
模型配置-文件类型:pickle格式
服务-名称:构建之后的服务名称
服务-版本前缀:构建使用的版本前缀,构建后会在版本上自动添加时间戳
输入-参数名:调用时输入的参数名称
输入-输入类型:调用时输入的参数类型
输出-参数名:调用时输出的参数名称
输出-输出类型:调用时输出的参数类型
Framework:使用的框架
依赖库:代码依赖的库
面板收起时,会自动保存步骤属性
部署
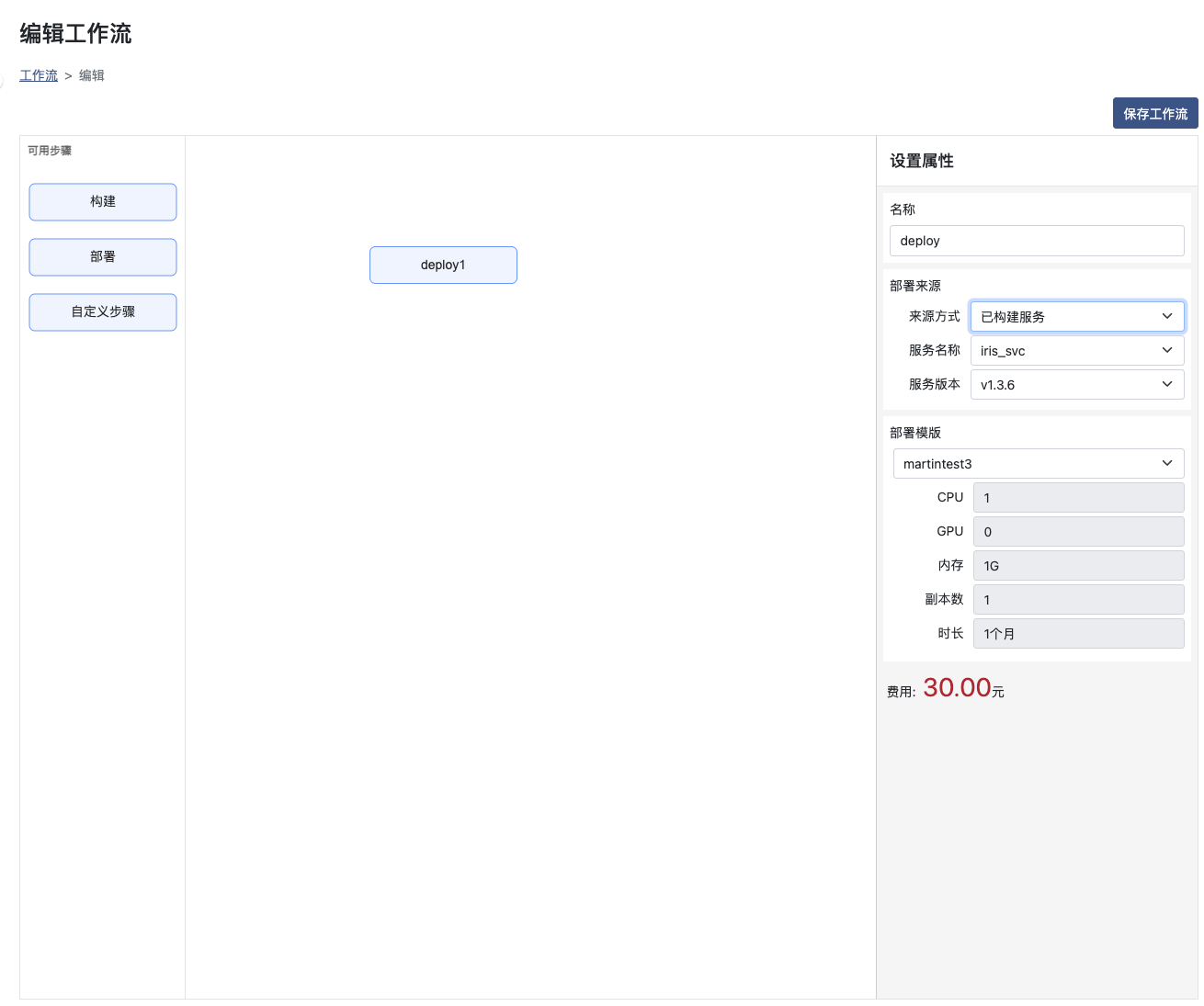
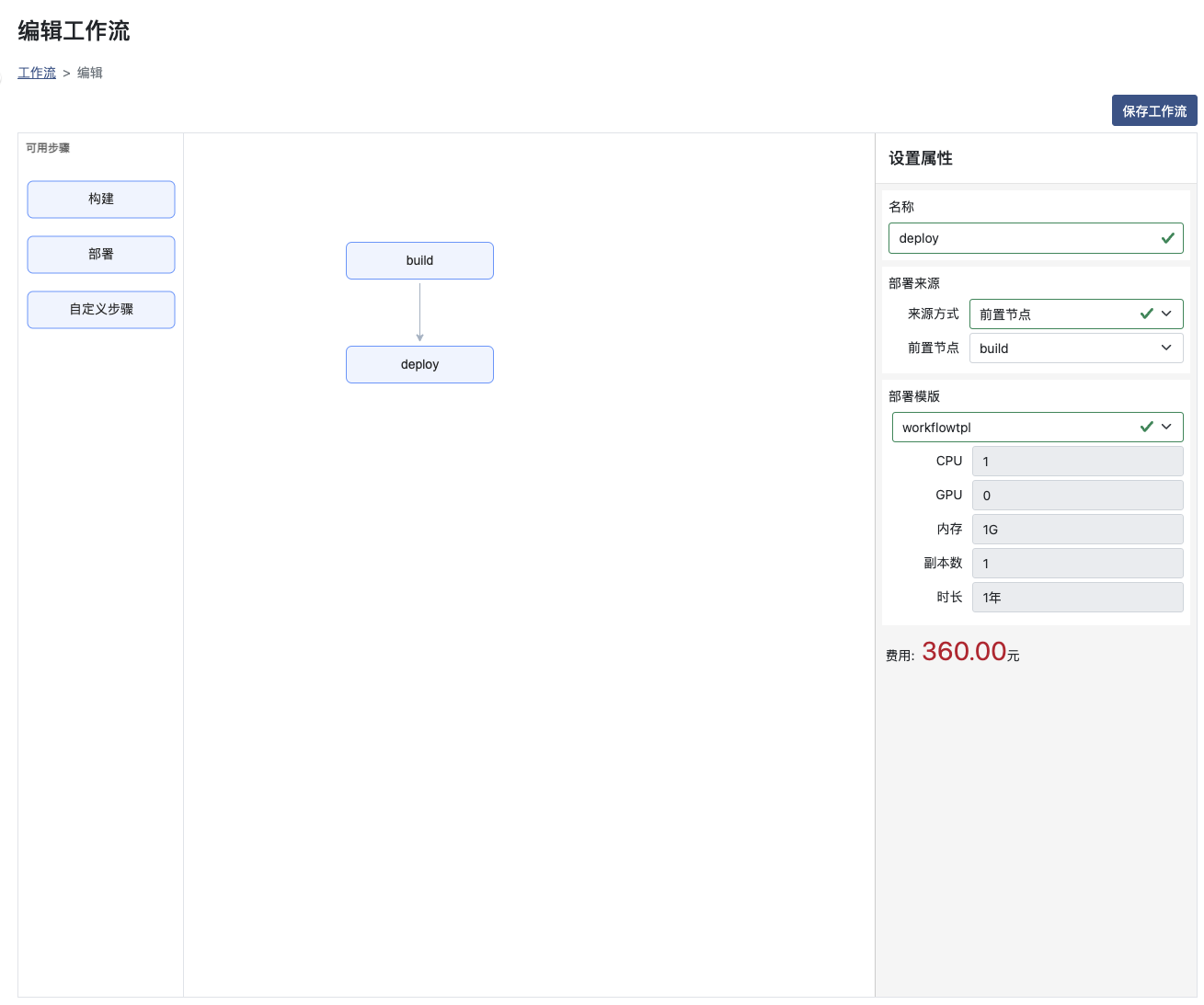
名称:需要唯一,且是以字母开头的数字字母组合;当部署名称不发生改变时,多次运行将重新部署对应服务
部署来源-来源方式:来源方式可选前置节点或已构建服务;选择前置节点,则需要保证该步骤前置为构建服务;选择已构建服务则需要选择已构建完成的服务和版本号
部署模版:选择一个对应的部署模版进行部署服务,部署模版的使用请参考部署模版部分
分布式训练
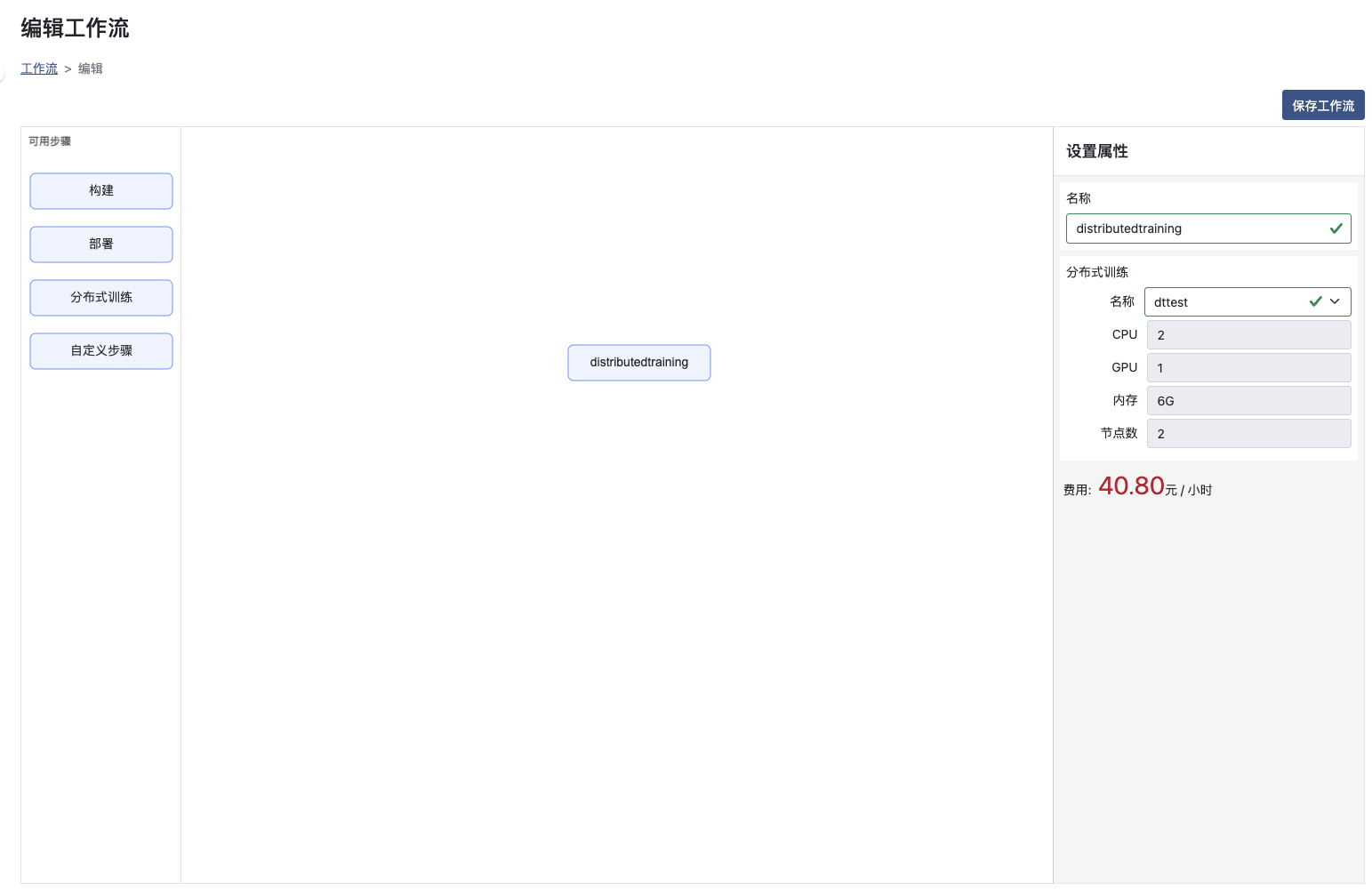
名称:选择已有的分布式训练,分布式训练的使用请参考创建分布式训练
训练 -> 构建 -> 部署 流程示例
创建名称为mnist的数据集,结构如下图
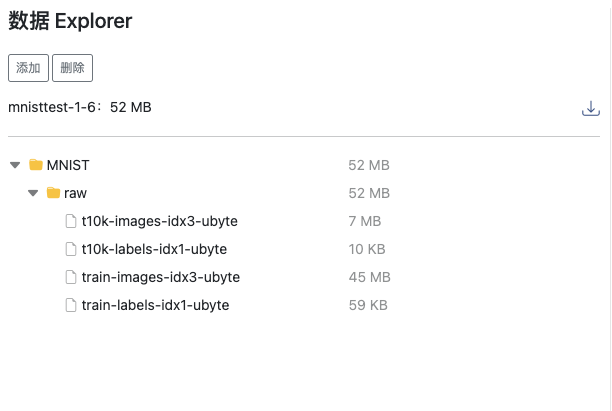
数据集的使用,请参照创建数据集
数据来源于
准备训练代码
import argparse
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import pickle
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
data_root = os.getenv("DATASET_mnist", ".")
workspace = os.getenv("WORKSPACE", ".")
print('training begin')
print(data_root)
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=1, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--dataset-folder', type=str, default=data_root, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
args = parser.parse_args()
# 如果存在GPU则使用GPU
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
if use_cuda:
print('running on GPU')
device = torch.device("cuda")
else:
device = torch.device("cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
dataset1 = datasets.MNIST(args.dataset_folder, train=True, download=True,
transform=transforms.ToTensor())
dataset2 = datasets.MNIST(args.dataset_folder, train=False,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
print('save model')
torch.save(model, workspace + "/mnist/model/mnist_cnn.pth")
if __name__ == '__main__':
main()
data_root = os.getenv("DATASET_mnist", ".")
workspace = os.getenv("WORKSPACE", ".")
以上代码使用了工作流步骤中内置的环境变量,工作流步骤中内置的环境变量请参照内置环境变量
可使用Notebook将代码保存至对应的工作空间下,路径如下图
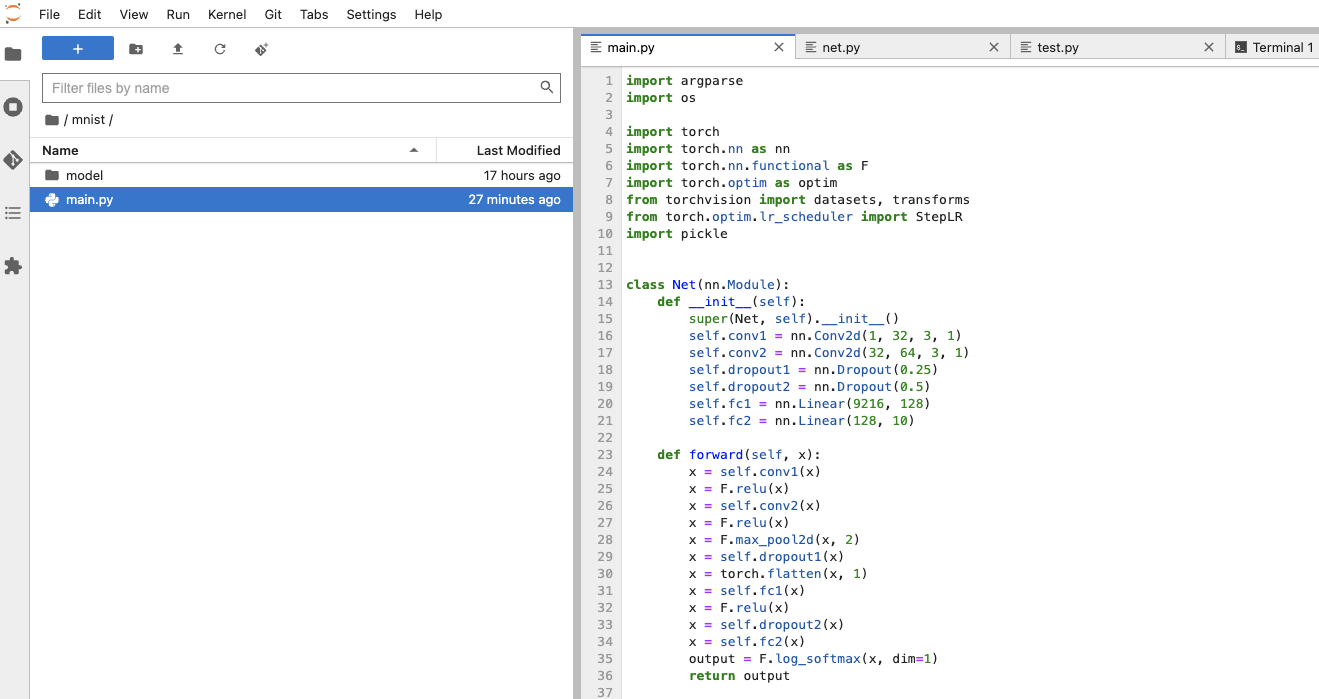
model文件夹:用于保存训练后的模型,且其中要包含Net定义文件
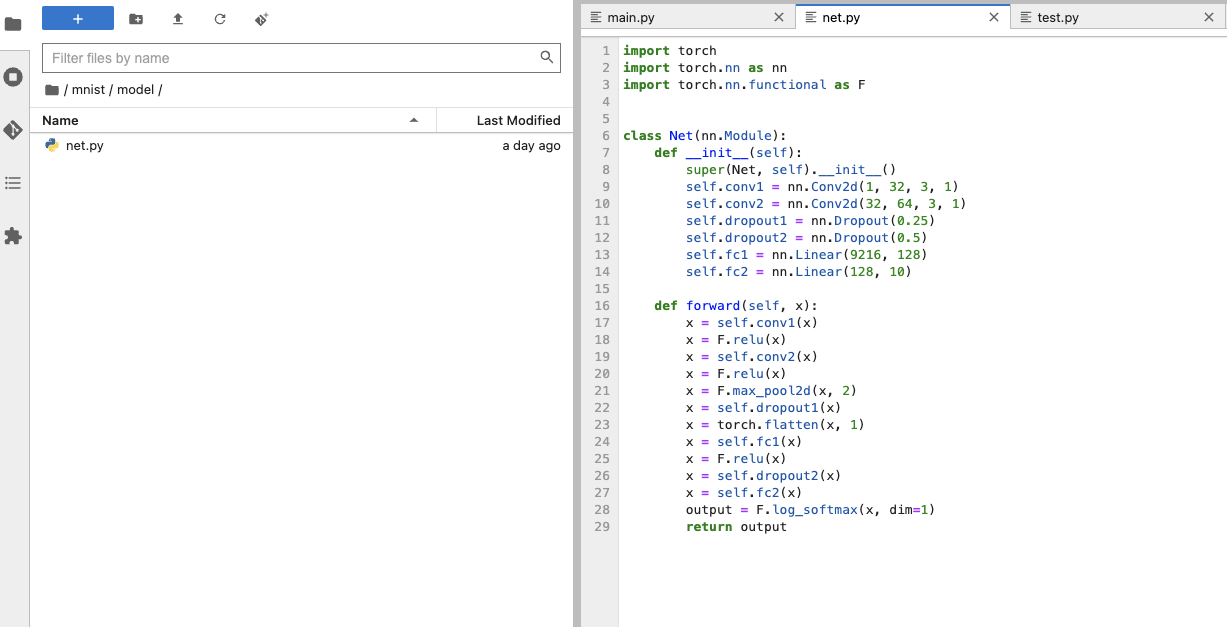
Net自定义文件:Net定义文件
比如如下代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
使用 自定义步骤 创建训练步骤,并设置属性如下
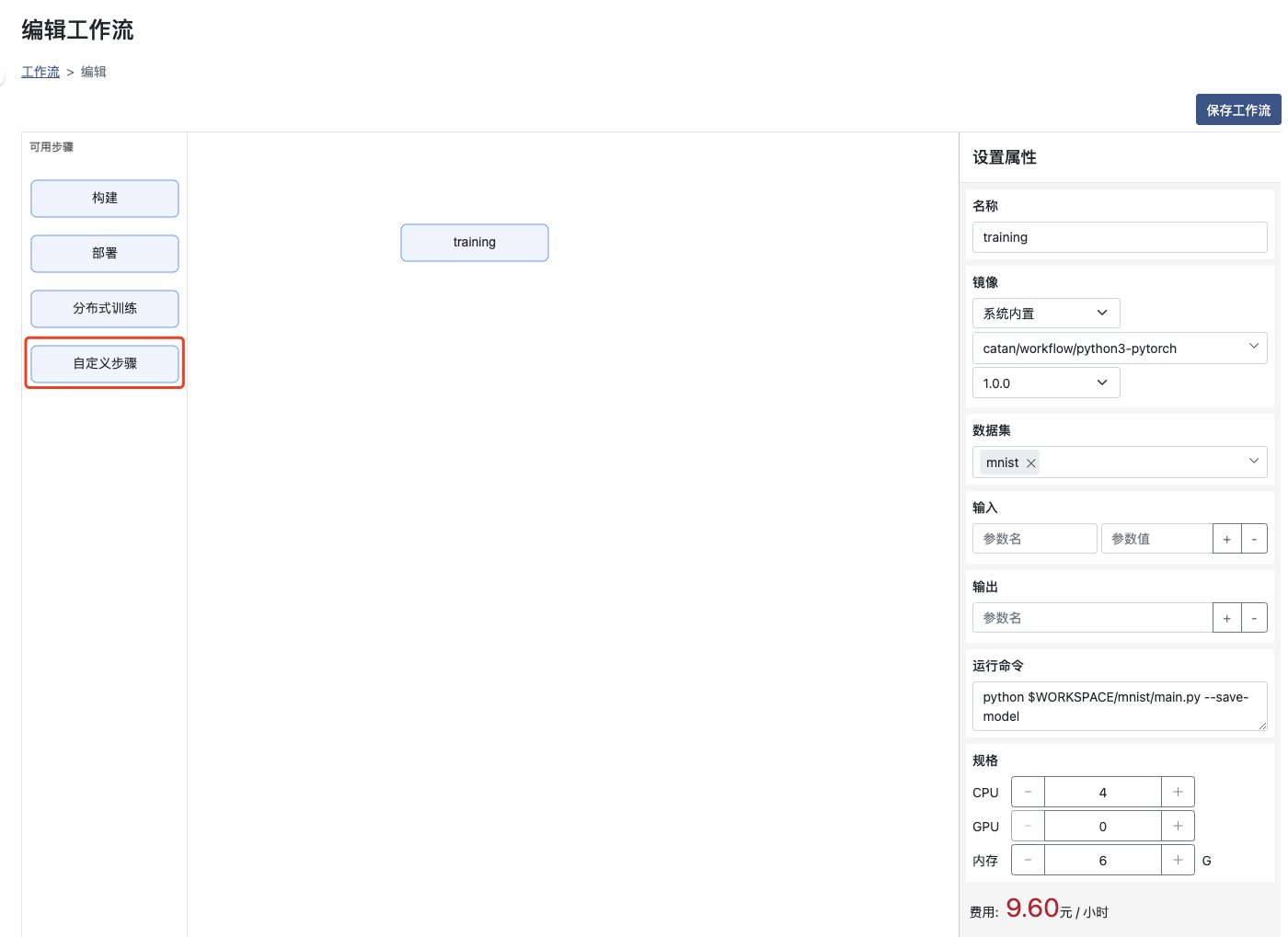
镜像:选择系统内置的对应框架镜像或者使用用户指定的镜像(用户指定需进行镜像配置)
数据集:选择mnist名称的数据集
运行命令:运行工作空间下对应的python文件
创建 构建 步骤,并设置打包参数
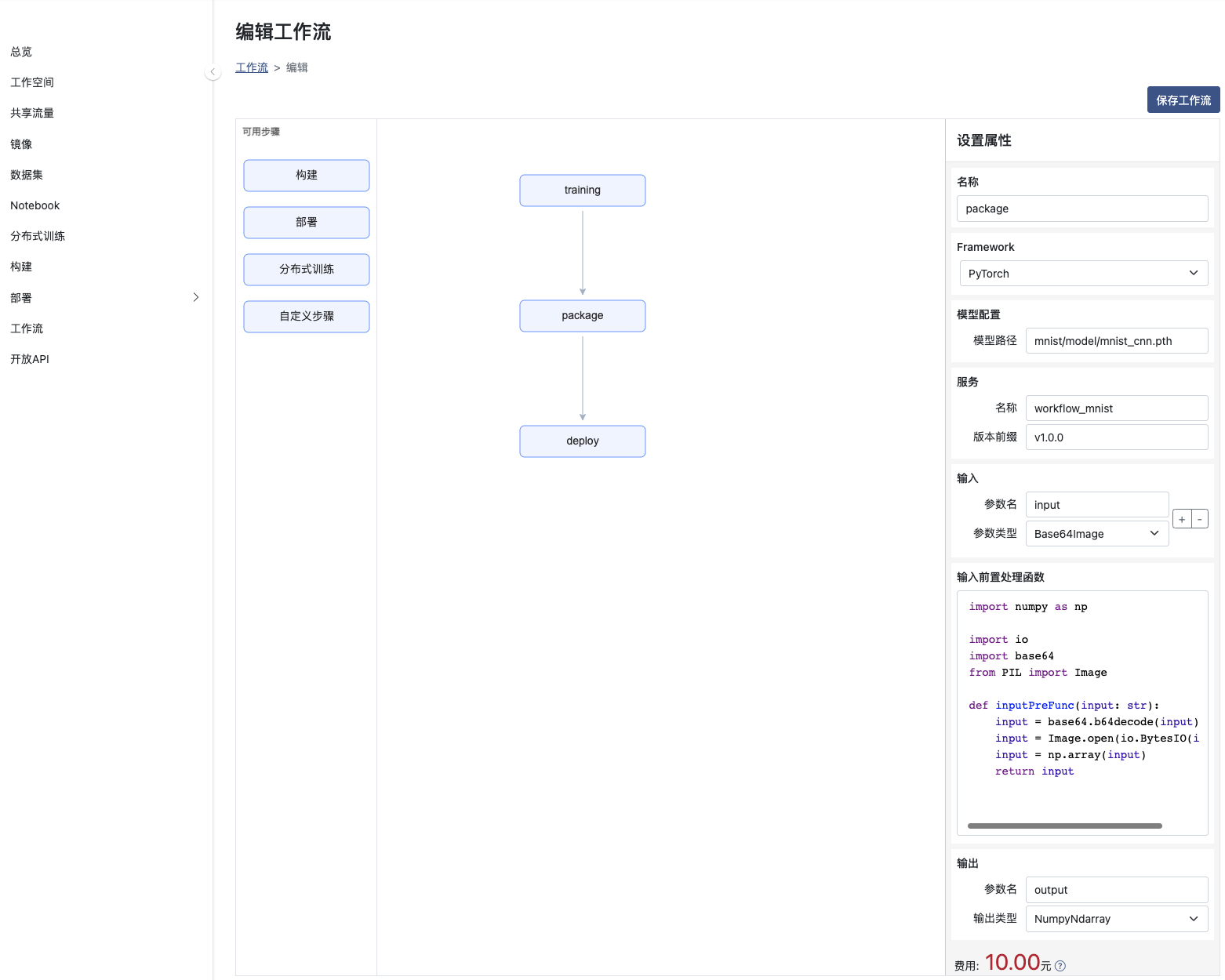
Framework:模型所使用的框架
模型路径: 模型打包文件存储路径, 上例模型存储路径为mnist/model/mnist_cnn.pth
服务名称: 模型打包文件对应的服务名称
版本前缀: 服务的版本前缀(工作流将自动添加一个时间戳作为后缀)
输入和输出: 模型数输入和输出名称和类型,目前输出仅支持NumpyNdarray类型
输入前置处理函数: 如果模型的输入需要根据自身业务进行一定的处理,则请将处理内容加入到函数中。如果您不提供相应的处理,系统将提供默认行为。
参数具体配置也可参考构建相关文档
此例子为PyTorch框架,其他框架的构建使用
PyTorch
Sklearn
Tensorflow
创建 部署 步骤,并设置属性
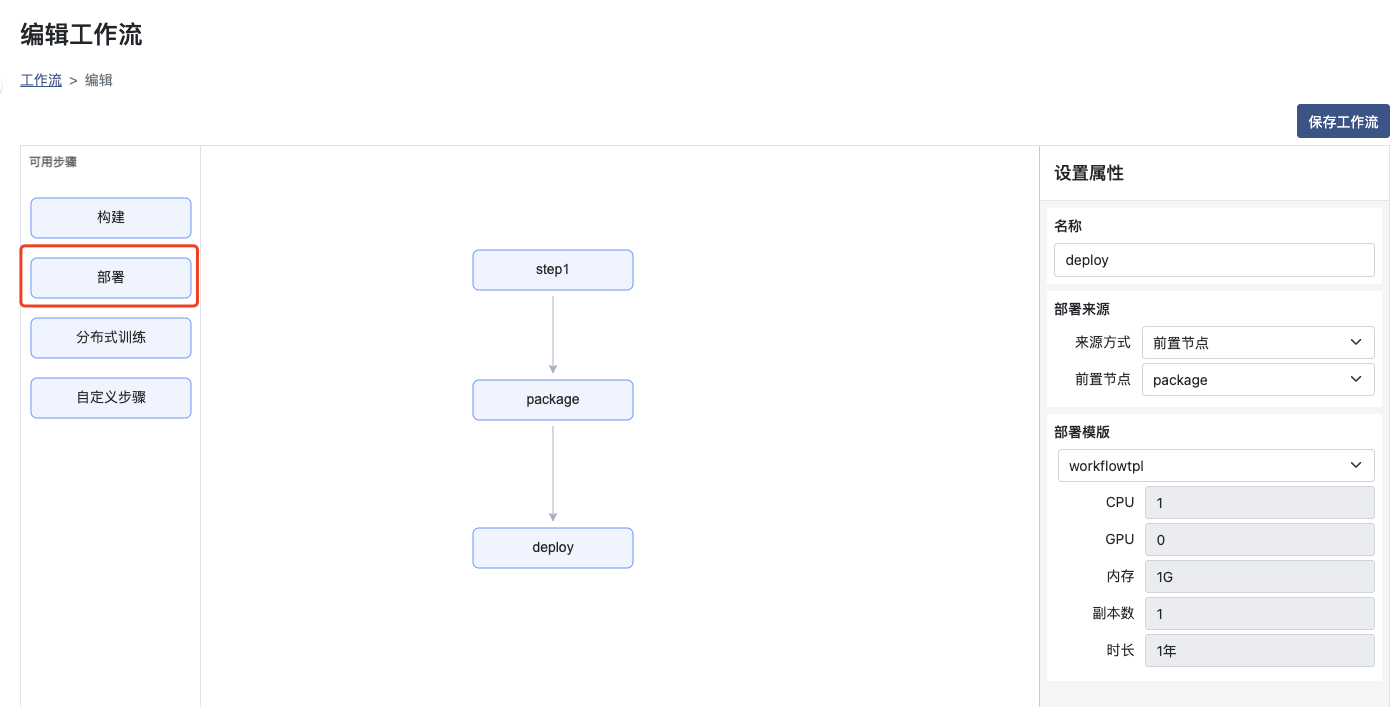
部署来源:前置节点选择构建步骤的名称
部署模版:选择已有的部署模版
点击右上的 保存工作流 进行工作流的保存后,可以选择在列表页进行运行或者设置定时运行
输入与输出参数的使用简单示例
创建带有输出参数的步骤
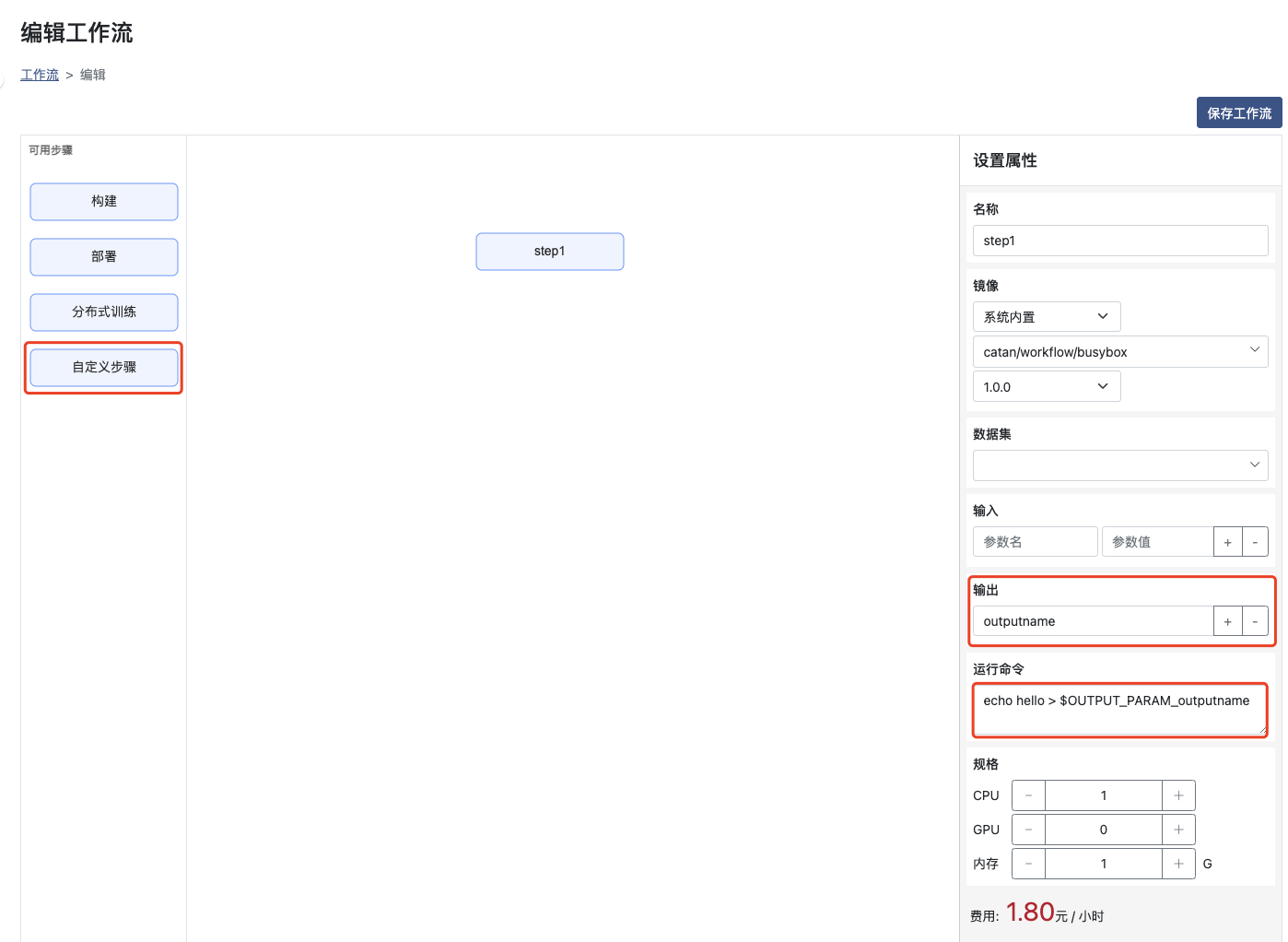
输出:输出变量的参数名称
运行命令:使用命令或者代码将需要输出的内容写入到 $OUTPUT_PARAM_输出参数名(环境变量名) 文件中,以便后置步骤可以使用输入参数来接收
环境变量 OUTPUT_PARAM_输出参数名 为完全的输出参数对应的文件名称
创建带有输入参数的步骤,并使用前置步骤的输出
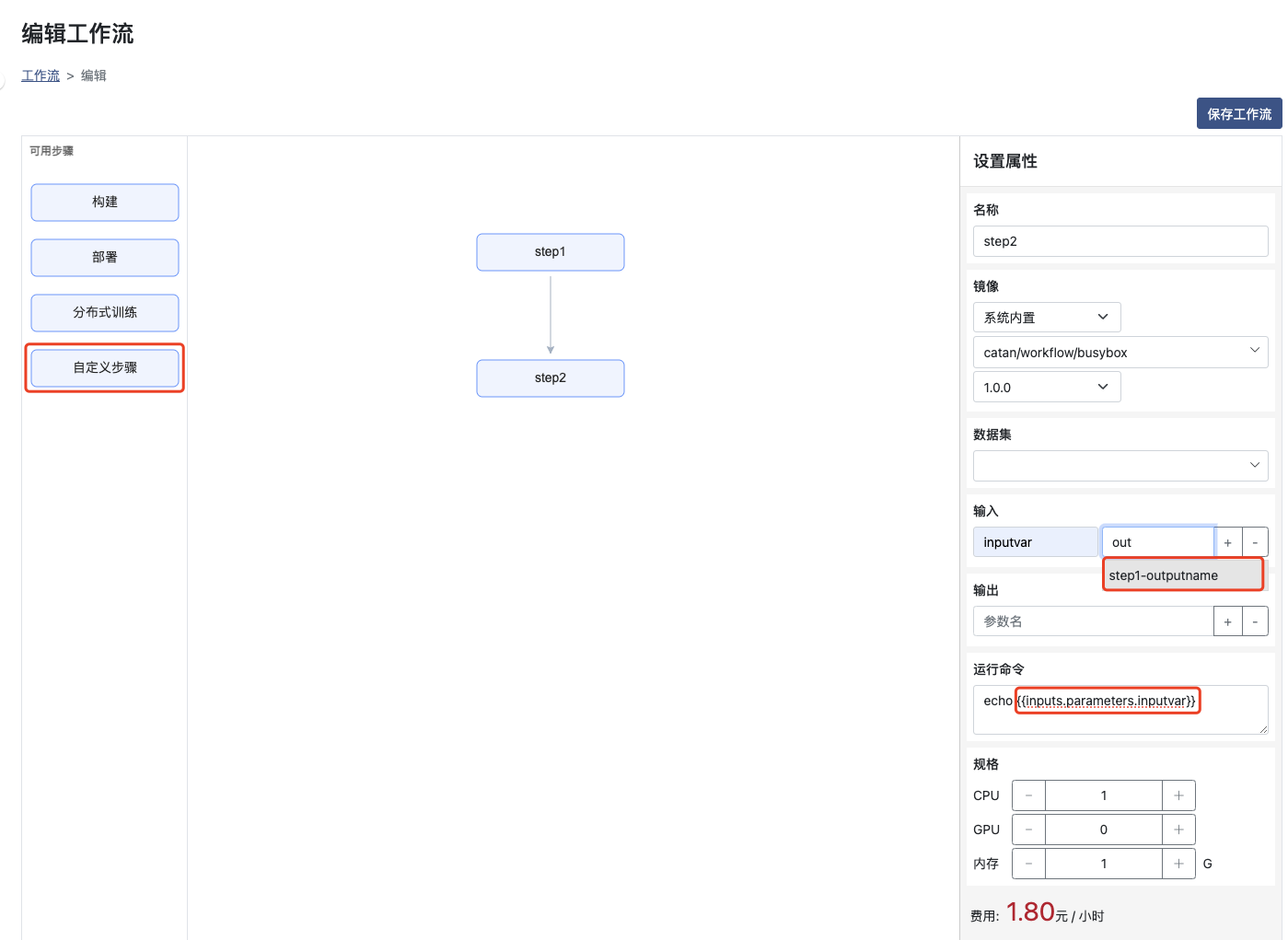
输入:填写 参数名称, 参数值 从提醒项中选择step1的 输出参数名
运行命令:命令中使用 {{inputs.parameters.输入参数名}} 获取对应的输入参数值,或者利用命令行传入到运行的代码中,如 python main.py {{inputs.parameters.inputval}}
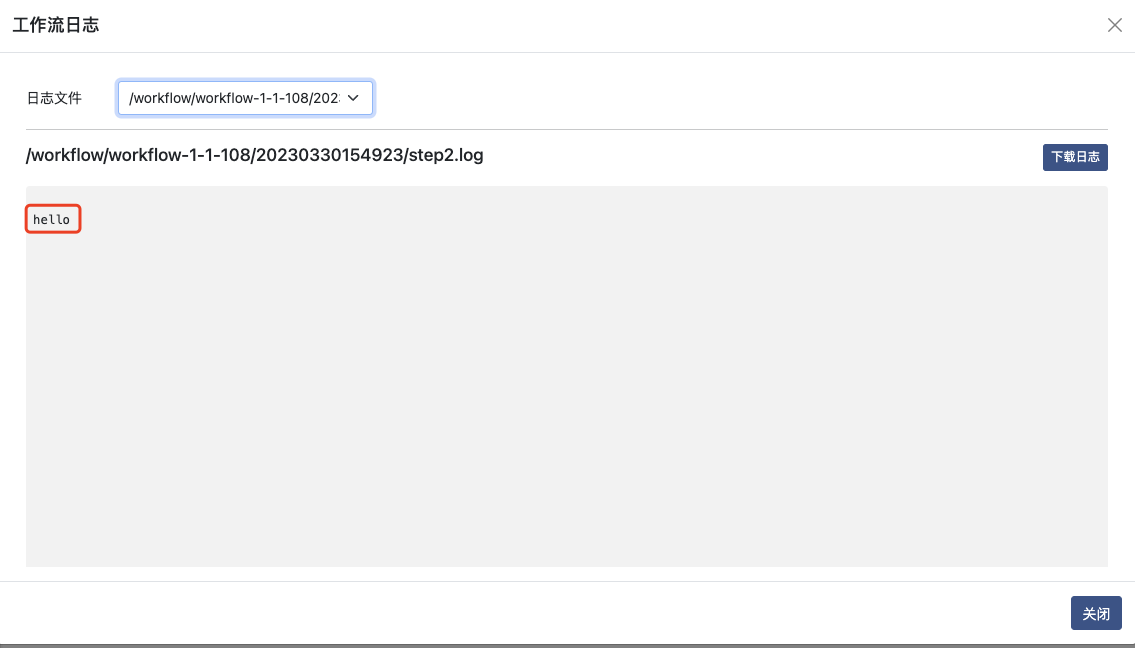
保存工作流,并在列表页面执行运行操作,得到step2的结果为step1的输出参数值"hello"
内置环境变量
| 环境变量名 | 说明 |
|---|---|
| WORKSPACE | 对应的工作空间路径 |
| DATASET_数据集名 | 对应挂载的数据集路径 |
| OUTPUT_PARAM_输出变量名 | 输出参数对应的文件全路径,使用命令或者代码将需要输出参数的值直接写入此文件 |