构建Scikit-Learn开发的模型
构建: 可将您已打包的模型进行容器化处理,方便模型资产的迁移和部署。
根据您使用的框架,AILines将针对不同的框架进行构建。
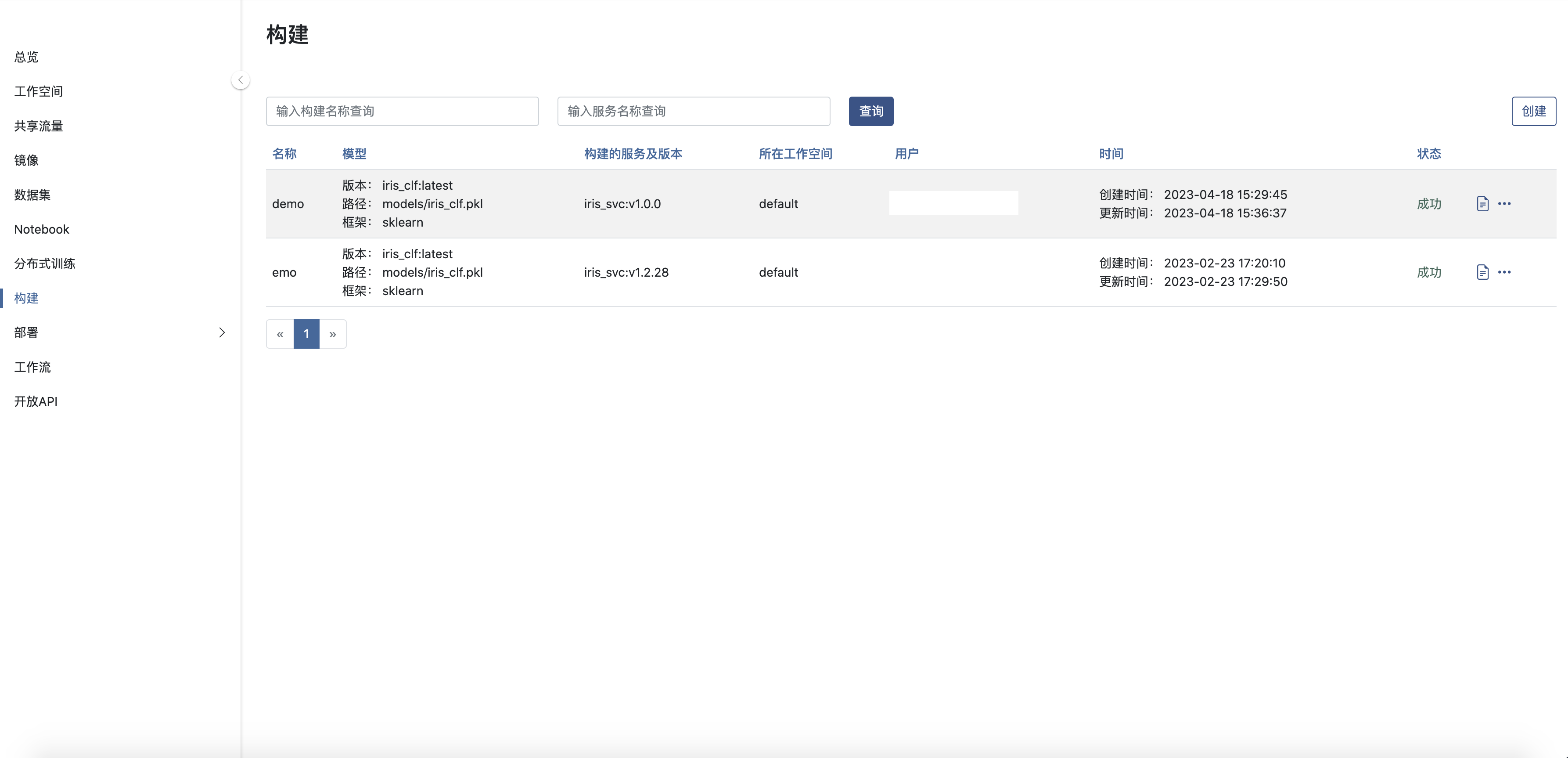
您可以在平台上创建修改构建,对构建的内容进行查看,删除等。
以 Scikit-Learn 框架为例,我们首先通过 Notebook 创建一个模型, 在模型评估后使用 Pickle 进行打包:
提示
关于如何启动Notebook,请参看:创建Notebook
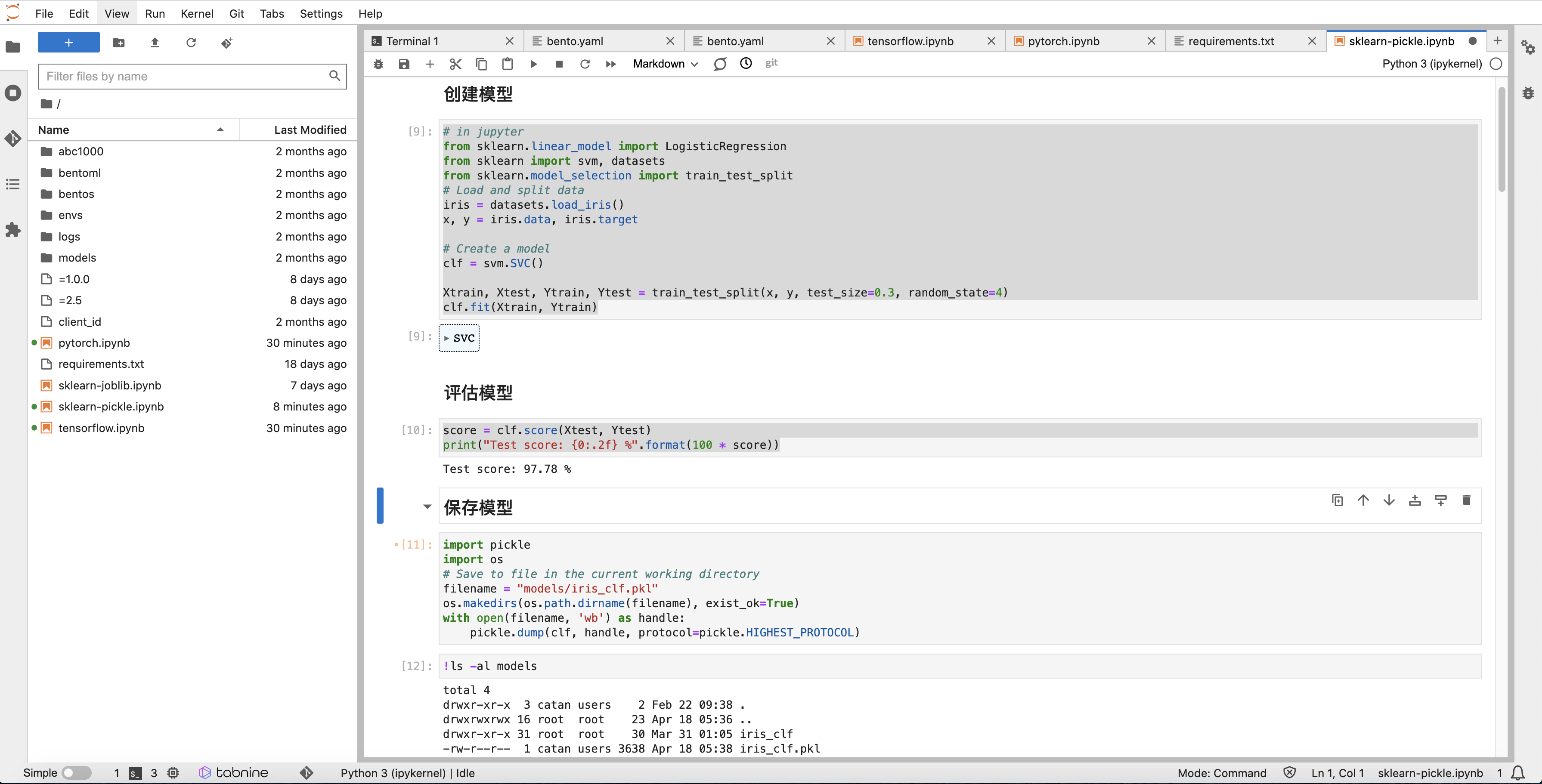
我们将打包的模型存储在工作空间的 models/iris_clf.pkl 路径中
提示
注意:Scikit-learn模型打包只能是pickle或joblib两种类型
如果是 Pickle 打包, 请使用 pkl 或 pickle 文件后缀
如果是 Joblib 打包, 请使用 joblib 文件后缀
创建构建
请点击构建列表页的 创建 按钮,跳转到模型构建页面,如下图:
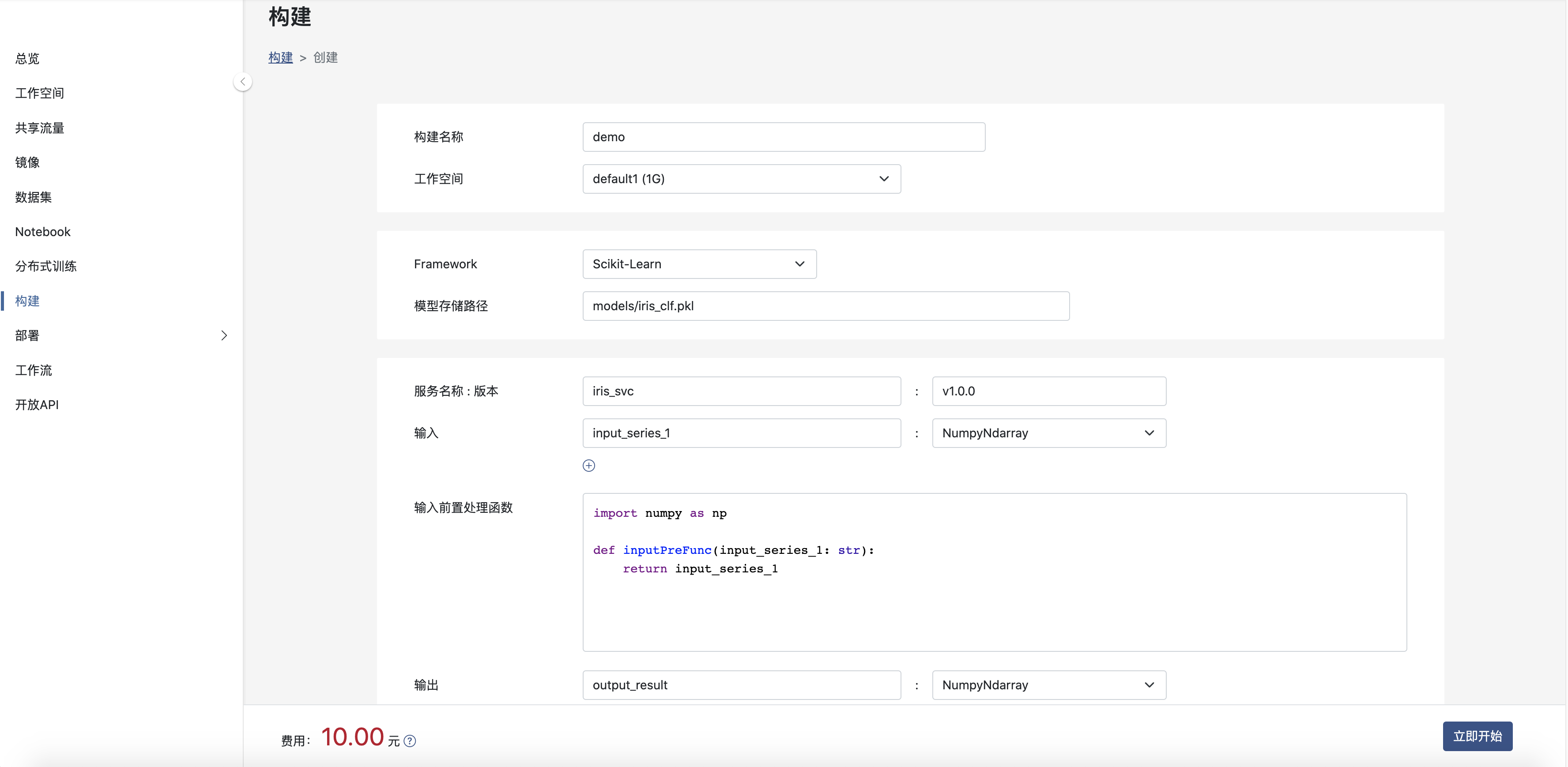
其中:
- 工作空间: 模型所在的工作空间。
- Framework: 模型所使用的框架。
- 模型存储路径: 模型打包文件存储路径, 上例模型存储路径为 models/iris_clf.pkl
- 服务名和版本: 将模型打包为服务,该模型的服务名称与版本号,服务名及版本号在租户内唯一。
- 输入和输出: 模型数输入和输出名称和类型,目前, 输入参数可选择 Base64Image 和 NumpyNdarray 两种类型,输出结果类型仅可以为NumpyNdarray。
- 输入前置处理函数: 如果模型的输入需要根据自身业务进行一定的处理,则请将处理内容加入到函数中。如果您不提供相应的处理,系统将提供默认行为。
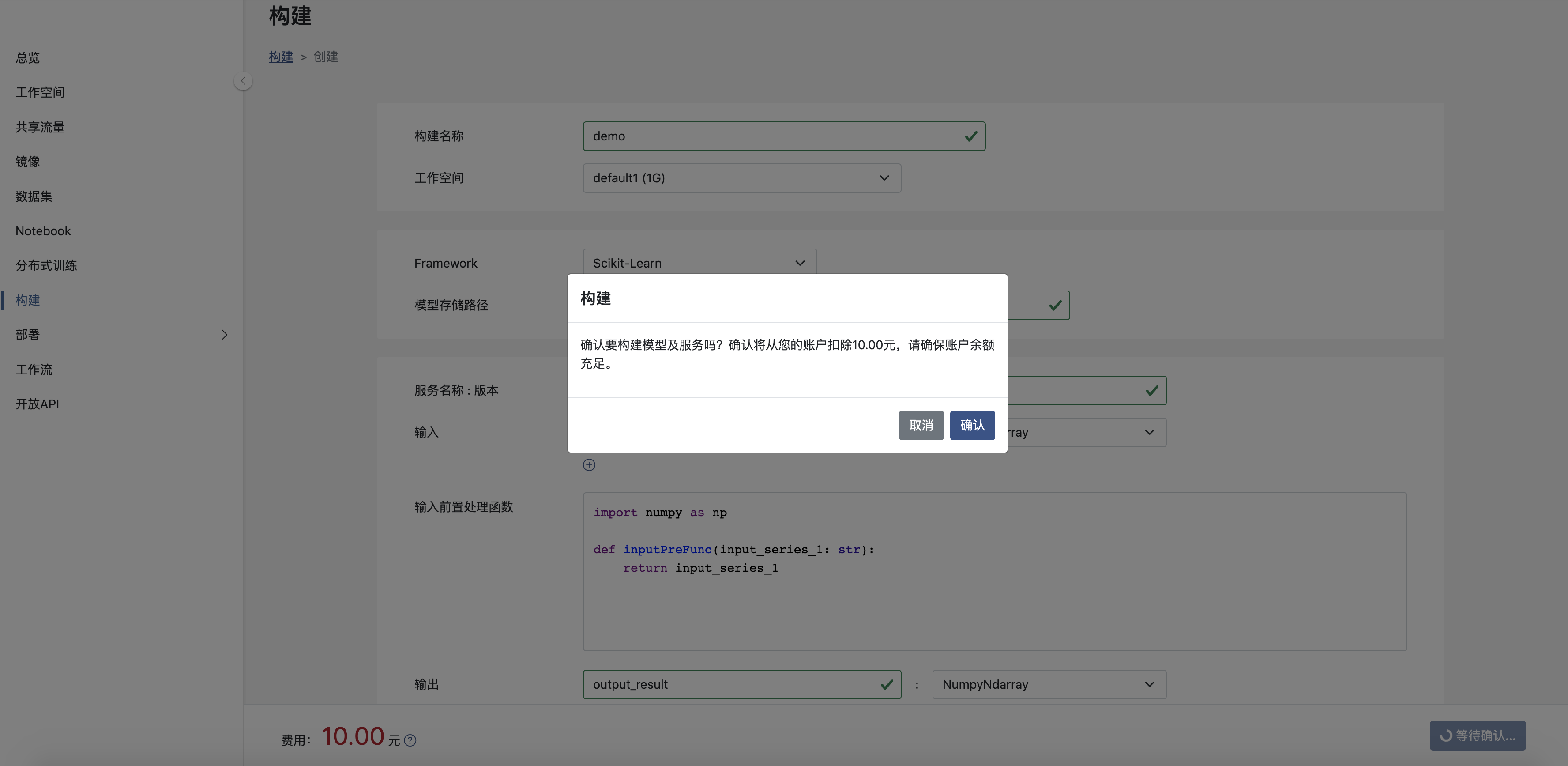
构建提交
确认提交构建后, 将跳转到构建列表页
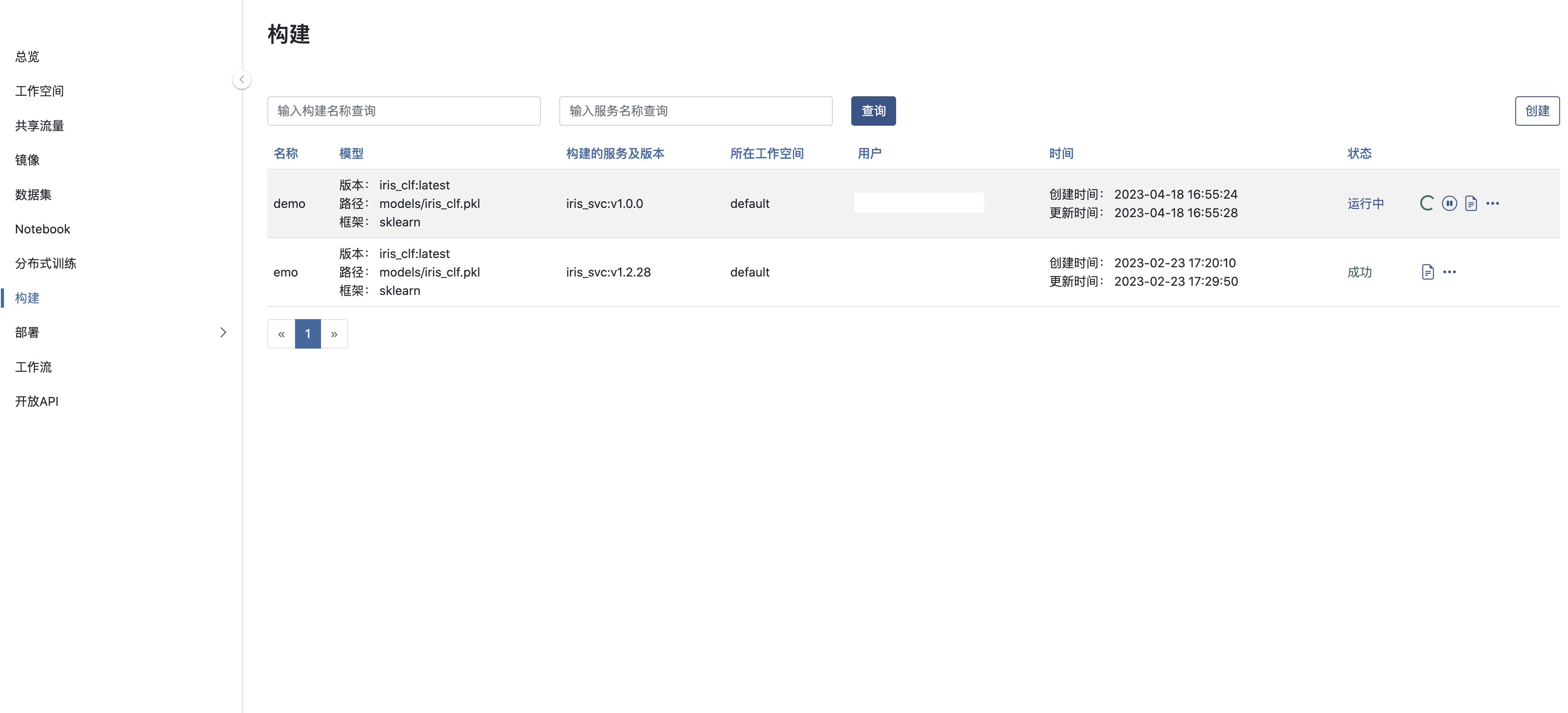
提交构建后,AILines将在后台将模型打包成服务, 一般需要等待5~10分钟,如果模型的复杂度高并且 Python 依赖多则等待时间会有所延长。
提示
如果您已经了解模型如何构建,请阅读下一节:
如何部署:模型部署
查看日志
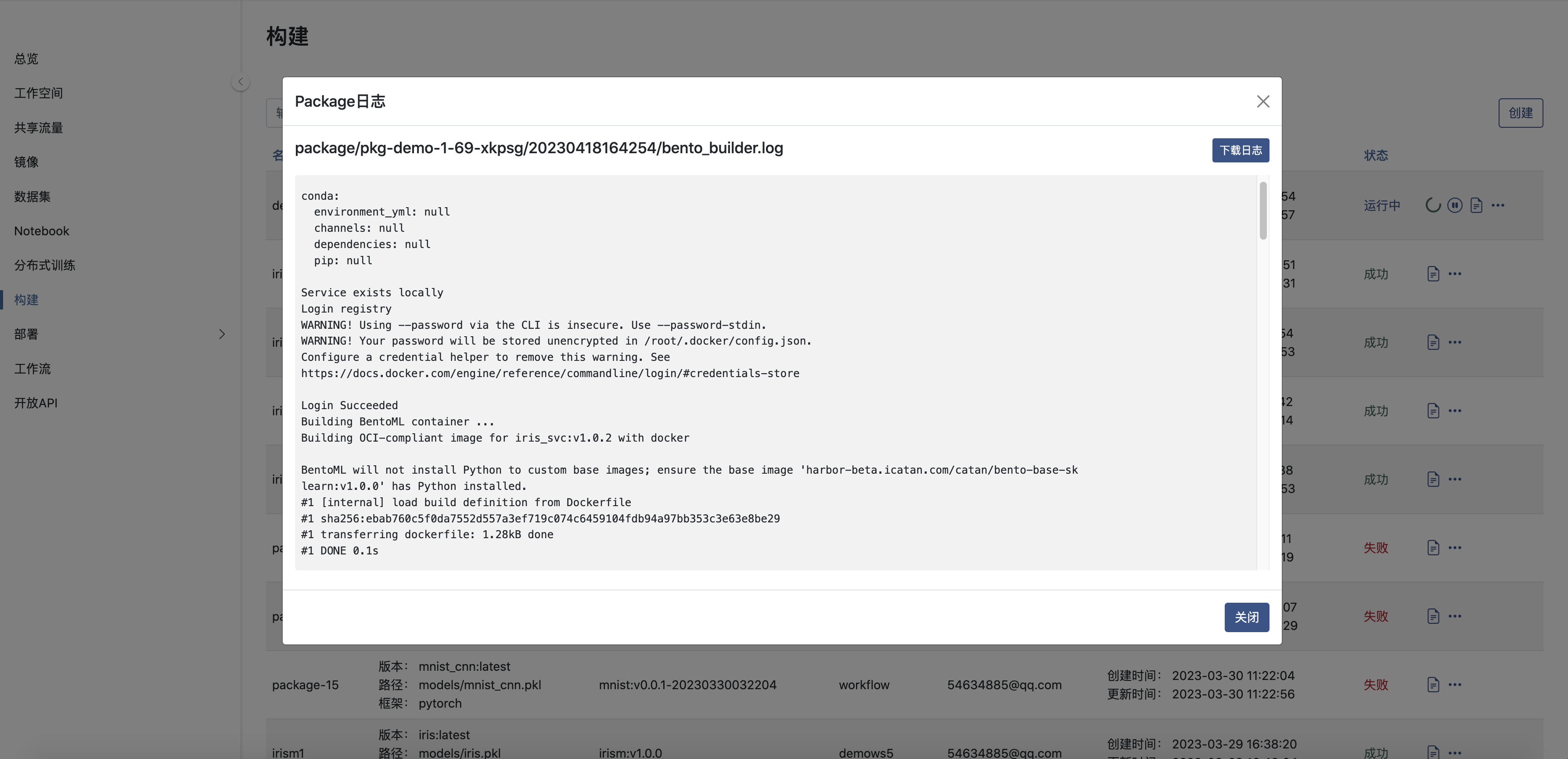
参考代码
import os
import pickle
from sklearn.linear_model import LogisticRegression
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
# 加载并拆分数据
iris = datasets.load_iris()
x, y = iris.data, iris.target
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x, y, test_size=0.3, random_state=4)
# 使用分类支持向量机创建模型
clf = svm.SVC()
# 训练
clf.fit(Xtrain, Ytrain)
# 评估
score = clf.score(Xtest, Ytest)
print("Test score: {0:.2f} %".format(100 * score))
# 保存模型
filename = "models/iris_clf.pkl"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, 'wb') as handle:
pickle.dump(clf, handle, protocol=pickle.HIGHEST_PROTOCOL)