分布式训练
在分布式训练中,训练模型的工作负载被拆分并在多个微型处理器(称为工作节点)之间共享。这些工作节点并行工作以加速模型训练。分布式训练可用于传统的ML模型,但更适合计算和时间密集型任务,例如用于训练深度神经网络的深度学习。
深度学习和分布式训练
分布式训练主要有两种类型:数据并行和模型并行。对于深度学习模型的分布式训练,AILines ML支持与流行框架PyTorch和TensorFlow进行集成,这两个框架都采用数据并行进行分布式训练。
数据并行
数据并行是两种分布式训练方法中最容易实现的,并且足以满足大多数用例。
在这种方法中,数据被划分为多个分区,其中分区数等于计算集群中可用节点的总数。该模型被复制到这些工作节点中的每一个中,并且每个工作节点都对自己的数据子集进行操作。请记住,每个节点都必须有能力支持正在训练的模型,即模型必须完全适合每个节点。下图(引用自azure)提供了此方法的可视化演示。

每个节点独立计算其训练样本预测与标记输出之间的误差。反过来,每个节点都会根据错误更新其模型,并且必须将其所有更改传达给其他节点以更新其相应的模型。这意味着工作节点需要在批量计算结束时同步模型参数或梯度,以确保它们正在训练一致的模型。
模型并行
在模型并行性(也称为网络并行性)中,模型被分割成不同的部分,这些部分可以在不同的节点上并发运行,并且每个部分都将在相同的数据上运行。这种方法的可扩展性取决于算法的任务并行化程度,实现起来比数据并行复杂。
在模型并行中,工作节点只需要同步共享参数,通常每个前向或后向传播步骤同步一次。此外,更大的模型也不是问题,因为每个节点都在相同训练数据的模型子部分上运行。
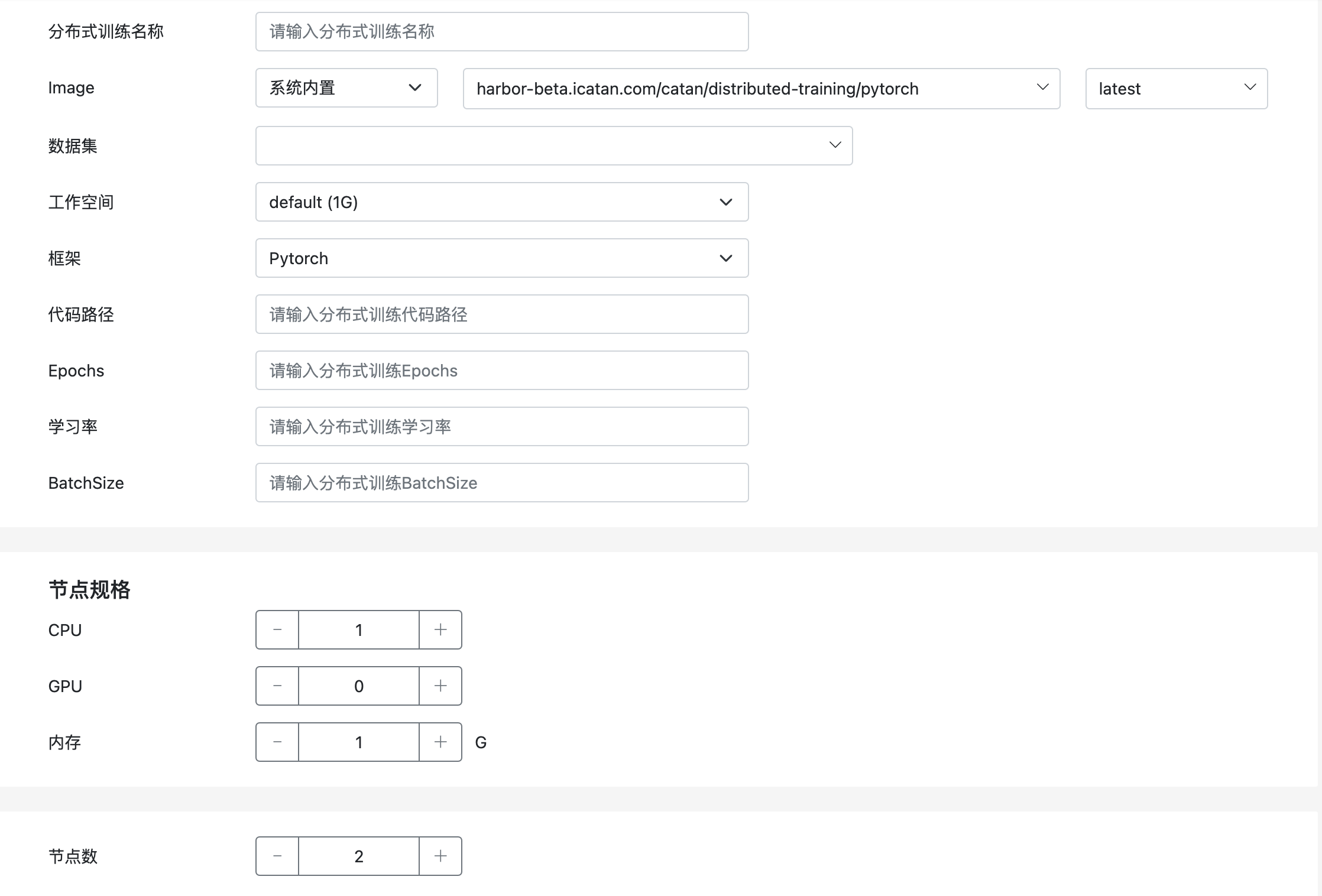
开通分布式训练服务
在用户控制台,可以开通分布式训练服务,如下图所示:
镜像
需要设置用于分布式训练任务运行的基础镜像,AILines ML默认提供了开箱即用的PyTorch和TensorFlow镜像,用户可以直接选择。当然也可以配置用户自己的镜像仓库进行选择。
数据集
分布式训练都需要使用依赖的数据集,可以提前创建好依赖的数据集,在创建分布式训练任务的时候进行选择。
AILines ML会在运行时,自动将其只读挂载到相应的目录,并为用户初始化以下环境变量。更详细的使用方式,请参考使用PyTorch进行分布式训练
DATASETS_PATH- AILines Dataset根目录,只读DATASETS- 训练所用到的Dataset名称列表,多个以逗号分隔
工作空间
选择合适的工作空间,工作空间是一种可写并且持久化的存储,可以用来存储代码、日志或者模型。
AILines ML会在运行时,自动将其可写挂载到相应的目录,并为用户初始化以下环境变量。
WORKSPACE- AILines Workspace根目录,持久化可读写
框架
AILines ML支持与流行框架PyTorch和TensorFlow。
代码路径
需要提前将训练代码存储到工作空间中,并在创建分布式训练任务时,填写代码路径,例如:distributed_training/pytorch/MNIST/main.py
参数化
对于分布式训练任务中常用的概念Epochs、学习率和BatchSize,我们提供了参数化支持。
AILines ML会在运行时,为用户初始化以下环境变量。
EPOCHS- 购买分布式训练产品所指定的EpochsLR- 购买分布式训练产品所指定的学习率BATCH_SIZE- 购买分布式训练产品所指定的BatchSize
工作节点
需要指定用于分布式训练任务的每个工作节点的规格以及一共需要多少个工作节点,根据不同规格和数量,价格也是不相同的,详细请参考定价模型。
使用PyTorch进行分布式训练
AILines ML支持使用PyTorch的本机分布式训练功能 (torch.distributed) 运行分布式训练任务。
进程组初始化
任何分布式训练都是基于一组相互了解并可以使用后端相互通信的进程。对于PyTorch来说,进程组是通过在所有分布式进程中调用torch.distributed.init_process_group来创建的,共同组成一个进程组。
torch.distributed.init_process_group(backend='nccl', init_method='env://', ...)
最常用的通信后端是mpi、nccl和gloo。对于基于GPU的训练,使用nccl可以获得最佳性能,而对于CPU的训练,推荐使用gloo。mpi是一个可选的后端,只有在从源代码构建PyTorch时才能包含它。(例如,在安装了mpi的主机上构建PyTorch。)
AILines ML会自动根据用户所使用的设备类型选择合适的通信后端,并可以通过环境变量BACKEND获得,从而进行PyTorch的设备初始化。
local_rank = args.local_rank
backend = os.getenv("BACKEND", "nccl")
if backend == 'nccl':
device = torch.device("cuda:{}".format(local_rank))
else:
device = torch.device("cpu:{}".format(local_rank))
init_method告诉每个进程如何相互发现,它们如何使用通信后端初始化和验证进程组。默认情况下,如果未指定 init_method,PyTorch 将使用环境变量初始化方法 (env://)。 init_method是在训练代码中使用的初始化方法,用于在AILines ML上运行分布式PyTorch。AILines ML会自动初始化分布式PyTorch所需的环境变量:
MASTER_ADDR- rank 0进程所在节点的IP地址MASTER_PORT- rank 0进程所在节点的可用端口WORLD_SIZE- 进程总数,应等于用于分布式训练的设备(GPU/CPU)总数RANK- 当前进程的(全局)排名,可能的值是0到(WORLD_SIZE- 1)
有关进程组初始化的更多信息,请参阅PyTorch文档。 除此之外,许多应用程序还需要以下环境变量:
LOCAL_RANK- 节点内进程的本地(相对)排名。可能的值为0到(节点上的进程数 - 1),此信息很有用,因为许多操作(例如数据准备)只应在每个节点上执行一次——通常在local_rank = 0时执行NODE_RANK- 多节点训练的节点排名,可能的值为0到(节点总数 - 1)
AILines ML已经提前初始化好了NODE_RANK环境变量,可以直接获取。LOCAL_RANK比较特殊,如果一个节点上有多个(GPU/CPU)设备,那么torch.distributed.launch会自动的在该节点上再启动相应的进程绑定设备进行分布式训练,可以通过程序来进行初始化和获取LOCAL_RANK。
import argparse
parser = argparse.ArgumentParser()
# 注意这个参数,必须要以这种形式指定,即使代码中不使用。因为 launch 工具默认传递该参数
parser.add_argument('--local_rank', type=int, help="local gpu/cpu device id")
args = parser.parse_args()
local_rank = args.local_rank
AILines ML还会根据用户所购买的分布式训练产品初始化以下的环境变量,方便用户进行程序的参数化。
DATASETS_PATH- AILines Dataset根目录,只读DATASETS- 训练所用到的Dataset名称列表,多个以逗号分隔WORKSPACE- AILines Workspace根目录,持久化可读写BATCH_SIZE- 购买分布式训练产品所指定的BatchSizeEPOCHS- 购买分布式训练产品所指定的EpochsLR- 购买分布式训练产品所指定的学习率WORKER_PER_NODE- 每个节点的进程数
MNIST分布式训练样例
例子中我们使用了Pytorch的公共数据集MNIST,您可以提前了解在AILines中如何方便的存储和使用Pytorch公共数据集。
import os
import argparse
import torch
import torchvision
from torch import distributed as dist
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
import numpy as np
world_size = int(os.getenv("WORLD_SIZE", 2))
batch_size = int(os.getenv("BATCH_SIZE", 128))
epochs = int(os.getenv("EPOCHS", 5))
lr = float(os.getenv("LR", 0.001))
backend = os.getenv("BACKEND", "nccl")
worker_per_node = int(os.getenv("WORKER_PER_NODE", 1))
workspace_path = os.getenv("WORKSPACE")
datasets_path = os.getenv("DATASETS_PATH")
def get_datasets():
# The mounted datasets will be separated by commas
datasets = os.getenv("DATASETS", "")
return datasets.split(",")
def get_dataset():
datasets = get_datasets()
if len(datasets) > 0:
return datasets[0]
return ""
def reduce_loss(tensor, rank):
with torch.no_grad():
dist.reduce(tensor, dst=0)
if rank == 0:
tensor /= world_size
parser = argparse.ArgumentParser()
# 注意这个参数,必须要以这种形式指定,即使代码中不使用。因为 launch 工具默认传递该参数
parser.add_argument('--local_rank', type=int, help="local gpu/cpu device id")
args = parser.parse_args()
dist.init_process_group(backend=backend, init_method='env://')
# Need to put tensor on a cpu/gpu device
local_rank = args.local_rank
device_ids = [local_rank]
output_device = local_rank
if backend == 'nccl':
device = torch.device("cuda:{}".format(local_rank))
else:
device = torch.device("cpu:{}".format(local_rank))
# For multi-device modules and CPU modules, it must be ``None``
device_ids = None
output_device = None
global_rank = dist.get_rank()
from torchvision.models.resnet import ResNet, BasicBlock
class MnistResNet(ResNet):
def __init__(self):
super(MnistResNet, self).__init__(BasicBlock, [2, 2, 2, 2], num_classes=10)
self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
def forward(self, x):
return torch.softmax(super(MnistResNet, self).forward(x), dim=-1)
net = MnistResNet()
net.to(device)
if backend == 'nccl':
# SyncBatchNorm layers only work with GPU modules
net = torch.nn.SyncBatchNorm.convert_sync_batchnorm(net)
net = DDP(net, device_ids=device_ids, output_device=output_device)
class ToNumpy(object):
def __call__(self, sample):
return np.array(sample)
data_root = "{}/{}".format(datasets_path, get_dataset())
# Data should be prefetched
# Download should be set to be False, because it is not multiprocess safe
"""
root (string): Root directory of dataset where ``MNIST/raw/train-images-idx3-ubyte``
and ``MNIST/raw/t10k-images-idx3-ubyte`` exist.
train (bool, optional): If True, creates dataset from ``train-images-idx3-ubyte``,
otherwise from ``t10k-images-idx3-ubyte``.
"""
train_set = MNIST(root=data_root,
download=False,
train=True,
transform=torchvision.transforms.Compose(
[ToNumpy(), torchvision.transforms.ToTensor()])
)
value_set = MNIST(root=data_root,
download=False,
train=False,
transform=torchvision.transforms.Compose(
[ToNumpy(), torchvision.transforms.ToTensor()])
)
sampler = DistributedSampler(train_set)
train_loader = DataLoader(train_set,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
sampler=sampler,
num_workers=worker_per_node)
value_loader = DataLoader(value_set,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=worker_per_node)
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=lr)
net.train()
for e in range(epochs):
print("Local Rank: {}, Epoch: {}, Training ...".format(local_rank, e))
# DistributedSampler deterministically shuffle data
# by seting random seed be current number epoch
# so if do not call set_epoch when start of one epoch
# the order of shuffled data will be always same
sampler.set_epoch(e)
for idx, (imgs, labels) in enumerate(train_loader):
imgs = imgs.to(device)
labels = labels.to(device)
output = net(imgs)
loss = criterion(output, labels)
opt.zero_grad()
loss.backward()
opt.step()
reduce_loss(loss, global_rank)
if idx % 10 == 0 and global_rank == 0 and local_rank == 0:
print('Epoch: {} step: {} loss: {}'.format(e, idx, loss.item()))
net.eval()
with torch.no_grad():
cnt = 0
total = len(value_loader.dataset)
for imgs, labels in value_loader:
imgs, labels = imgs.to(device), labels.to(device)
output = net(imgs)
predict = torch.argmax(output, dim=1)
cnt += (predict == labels).sum().item()
if global_rank == 0:
print('eval accuracy: {}'.format(cnt / total))