构建Tensorflow开发的模型
构建: 可将您已打包的模型进行容器化处理,方便您的模型资产迁移和部署。
根据您使用的框架,AILines将针对不同的框架进行构建。
以 Tensorflow 框架为例,我们首先通过 Notebook 创建一个模型
提示
关于如何启动Notebook,请参看:创建Notebook
定义模型网络,如下图:
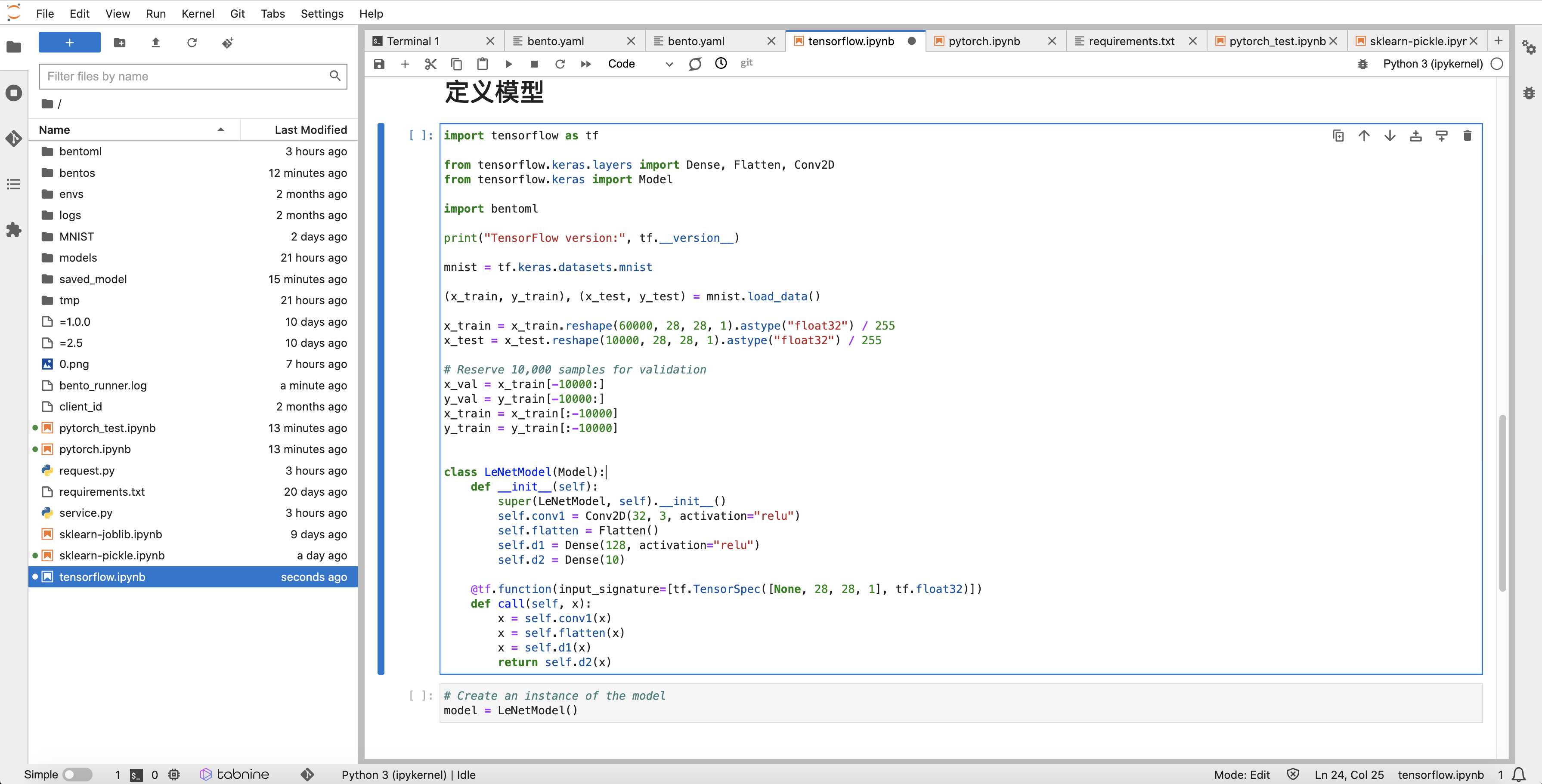
模型评估后使用 Tensorflow 原生 save 方式进行打包:
FilePath = './saved_model/tf_model'
tf.saved_model.save(model, f'{FilePath}')
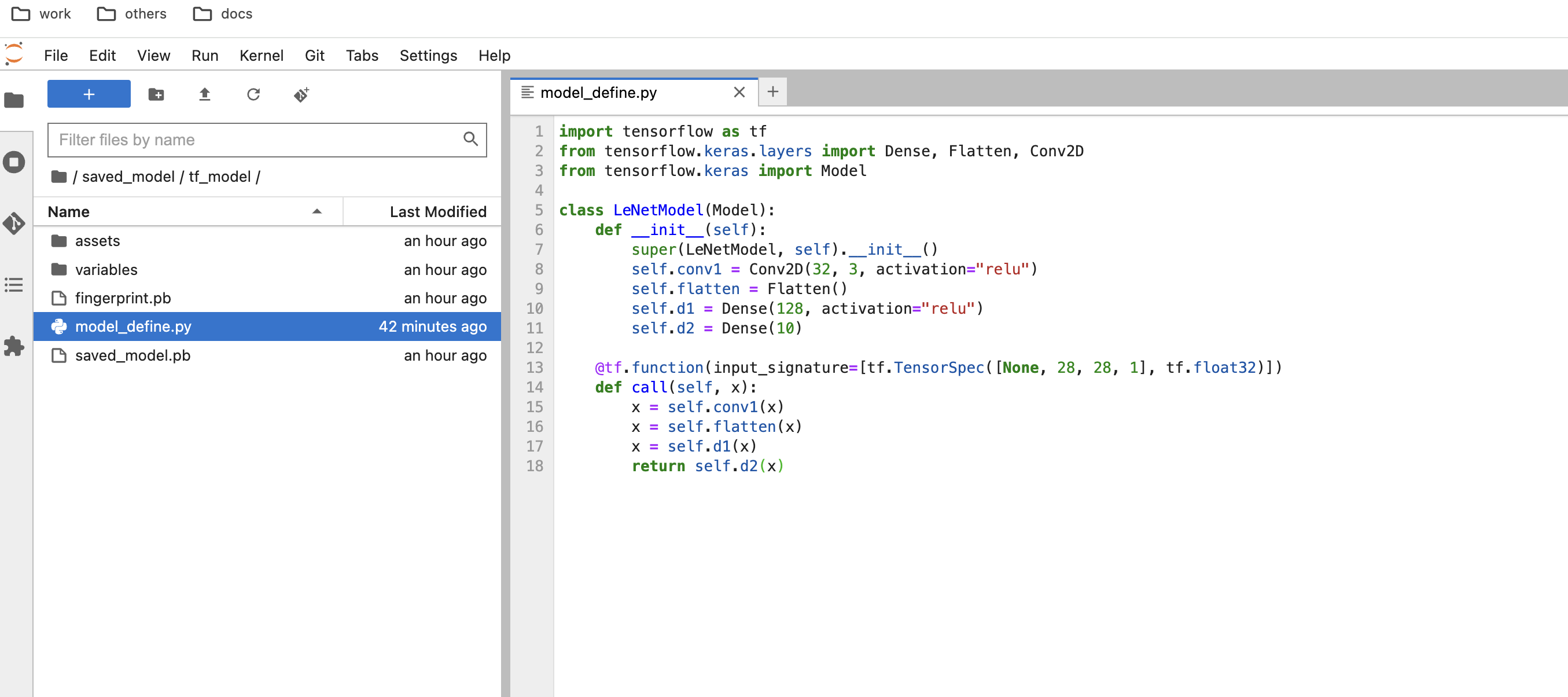
提示
如果您使用的是 自定义模型网络,请将网络定义文件也一并保存在 FilePath 的 同级目录 中
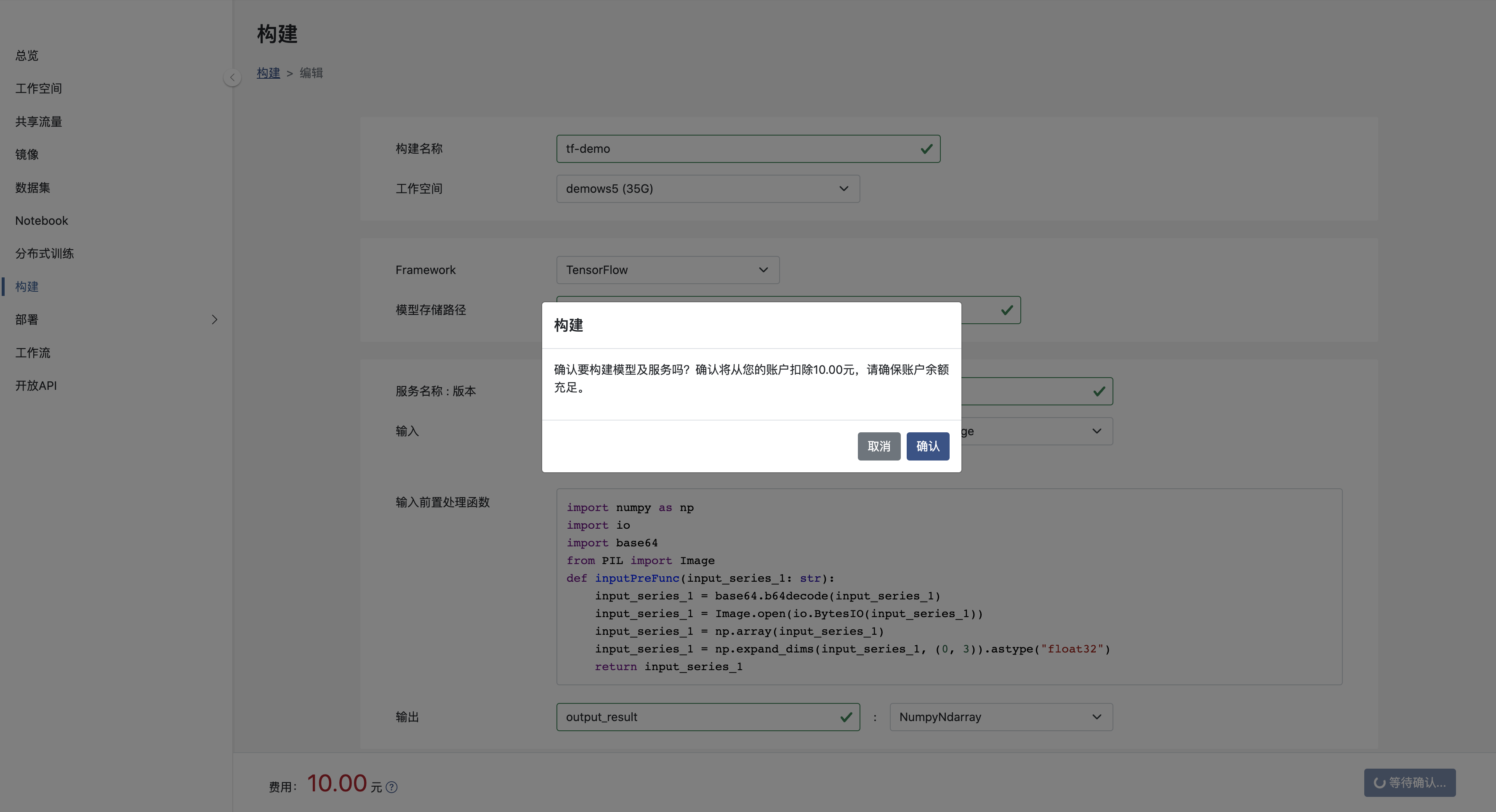
创建构建
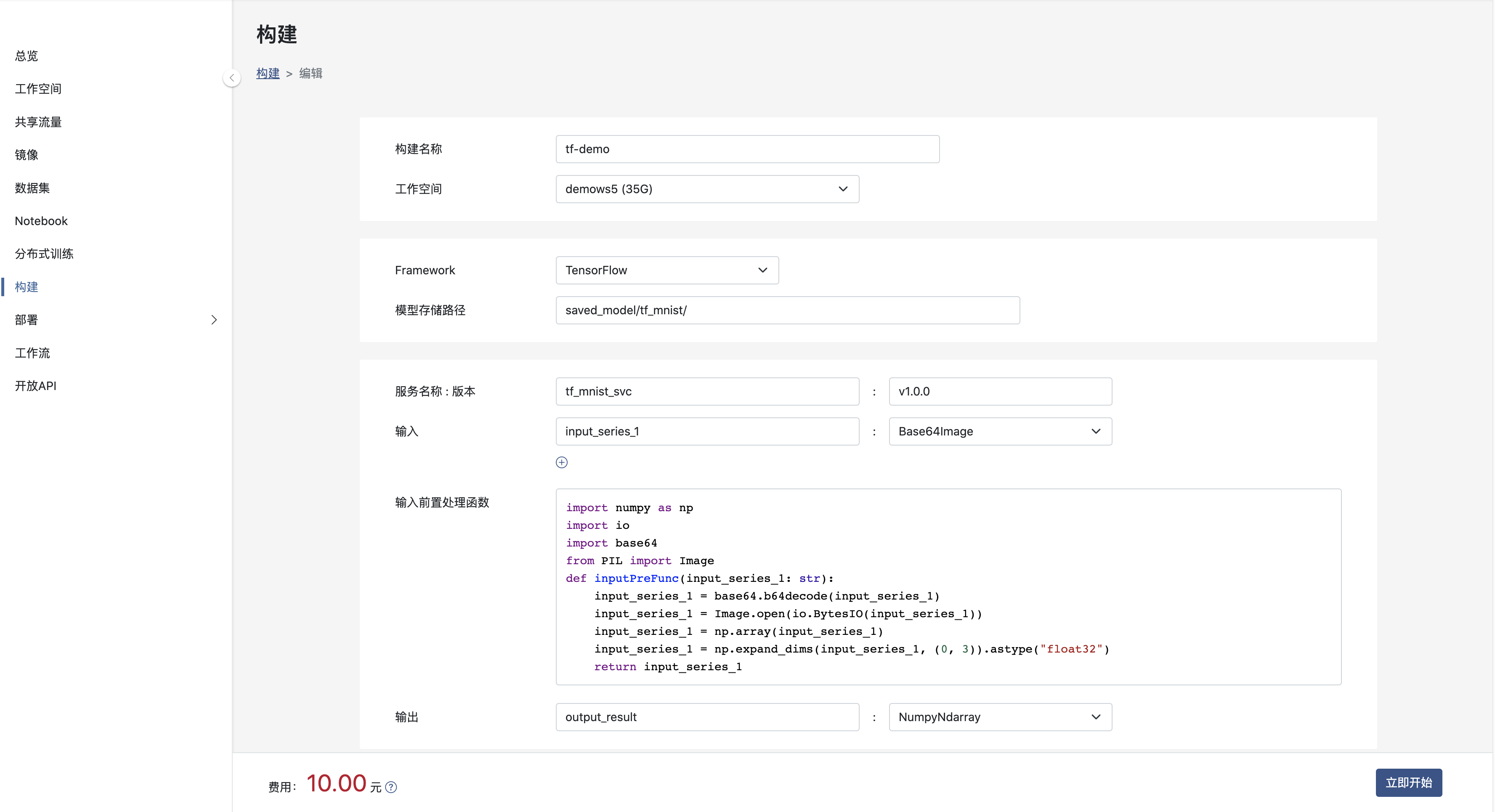
其中:
- 工作空间: 模型所在的工作空间。
- Framework: 模型所使用的框架。
- 模型存储路径: 模型打包文件存储路径, 上例模型存储路径为 saved_model/tf_mnist/。
- 服务名和版本: 将模型打包为服务,该模型的服务名称与版本号,服务名及版本号在租户内唯一。
- 输入和输出: 模型数输入和输出名称和类型,目前, 输入参数可选择 Base64Image 和 NumpyNdarray 两种类型,输出结果类型仅可以为NumpyNdarray。
- 输入前置处理函数: 如果模型的输入需要根据自身业务进行一定的处理,则请将处理内容加入到函数中。如果您不提供相应的处理,系统将提供默认行为。
提示
请注意:由于 Tensorflow 模型输出可能是一系列文件,所以对于 模型存储路径 请一定输入模型目录的完整路径并且以'/'为结尾,并保证该路径下没有其他干扰文件
提示
请注意:由于当前mnist手写体识别例子中模型使用图片作为输入,构建中请选择输入类型为 Base64Image
当输入类型为 Base64Image 时,输入前置处理函数 内容将自动加入处理代码。
构建提交
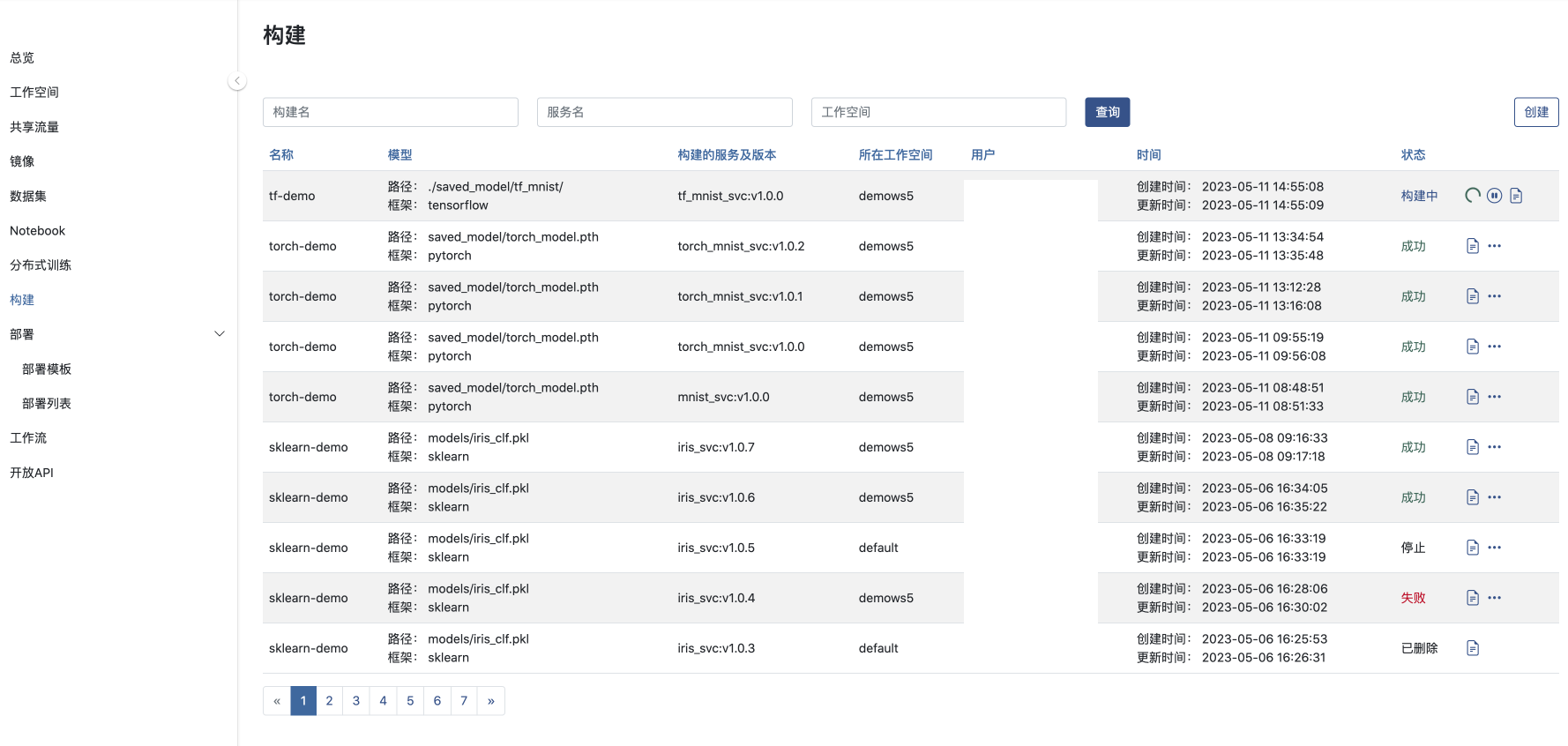
确认提交构建后, 将跳转到构建列表页
提交构建后,AILines将在后台将模型打包成服务, 一般需要等待5~10分钟,如果模型的复杂度高并且 Python 依赖多则等待时间会有所延长。
提示
关于如何部署,请参看:模型部署
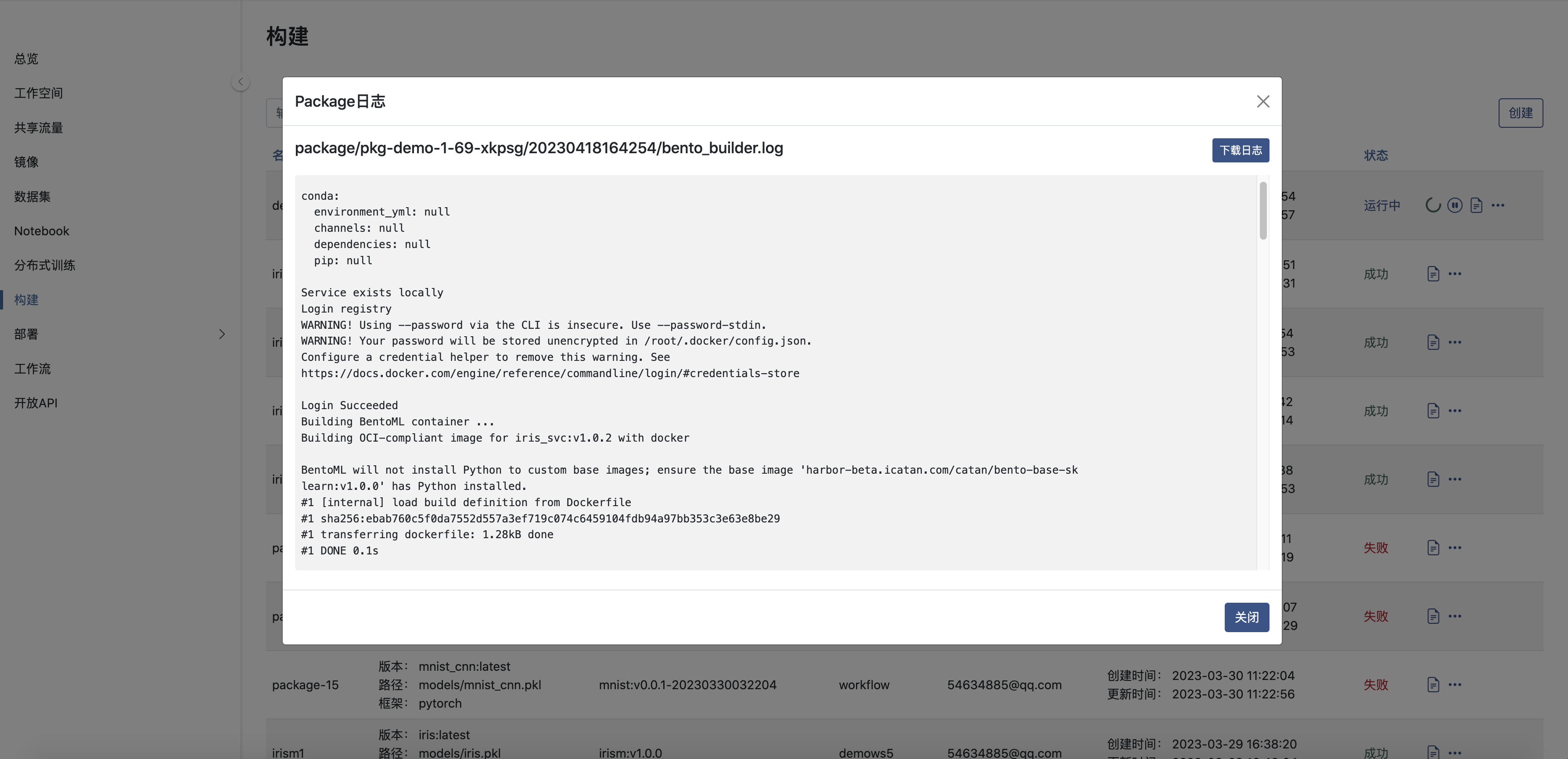
查看日志
Tensorflow参考代码
网络定义
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
class LeNetModel(Model):
def __init__(self):
super(LeNetModel, self).__init__()
self.conv1 = Conv2D(32, 3, activation="relu")
self.flatten = Flatten()
self.d1 = Dense(128, activation="relu")
self.d2 = Dense(10)
@tf.function(input_signature=[tf.TensorSpec([None, 28, 28, 1], tf.float32)])
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
拆分数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(path="/datasets/mnistpnz/mnist.npz")
x_train = x_train.reshape(60000, 28, 28, 1).astype("float32") / 255
x_test = x_test.reshape(10000, 28, 28, 1).astype("float32") / 255
# Reserve 10,000 samples for validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
训练并验证
model = LeNetModel()
model(x_test[0:1])
model.compile(
optimizer=tf.keras.optimizers.Adam(), # Optimizer
# Loss function to minimize
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
# List of metrics to monitor
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=1,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(x_val, y_val),
)
保存模型
tf.saved_model.save(model, './saved_model/tf_model')