构建Pytorch开发的模型
构建: 可将您已打包的模型进行容器化处理,方便您的模型资产迁移和部署。
根据您使用的框架,AILines将针对不同的框架进行构建。
以 Pytorch 框架为例,我们首先通过 Notebook 创建一个模型
提示
关于如何启动Notebook,请参看:创建Notebook
定义模型网络,如下图:
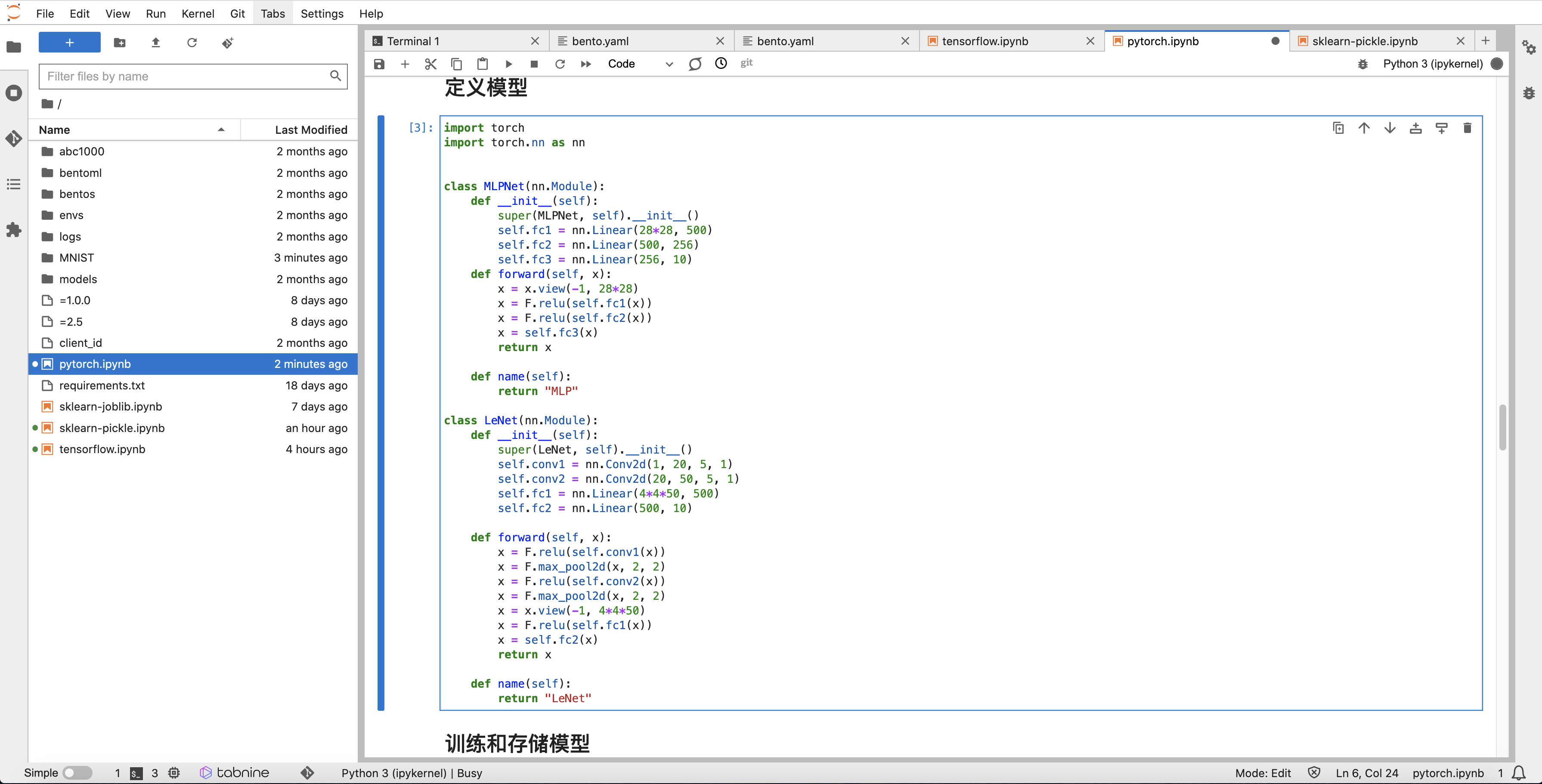
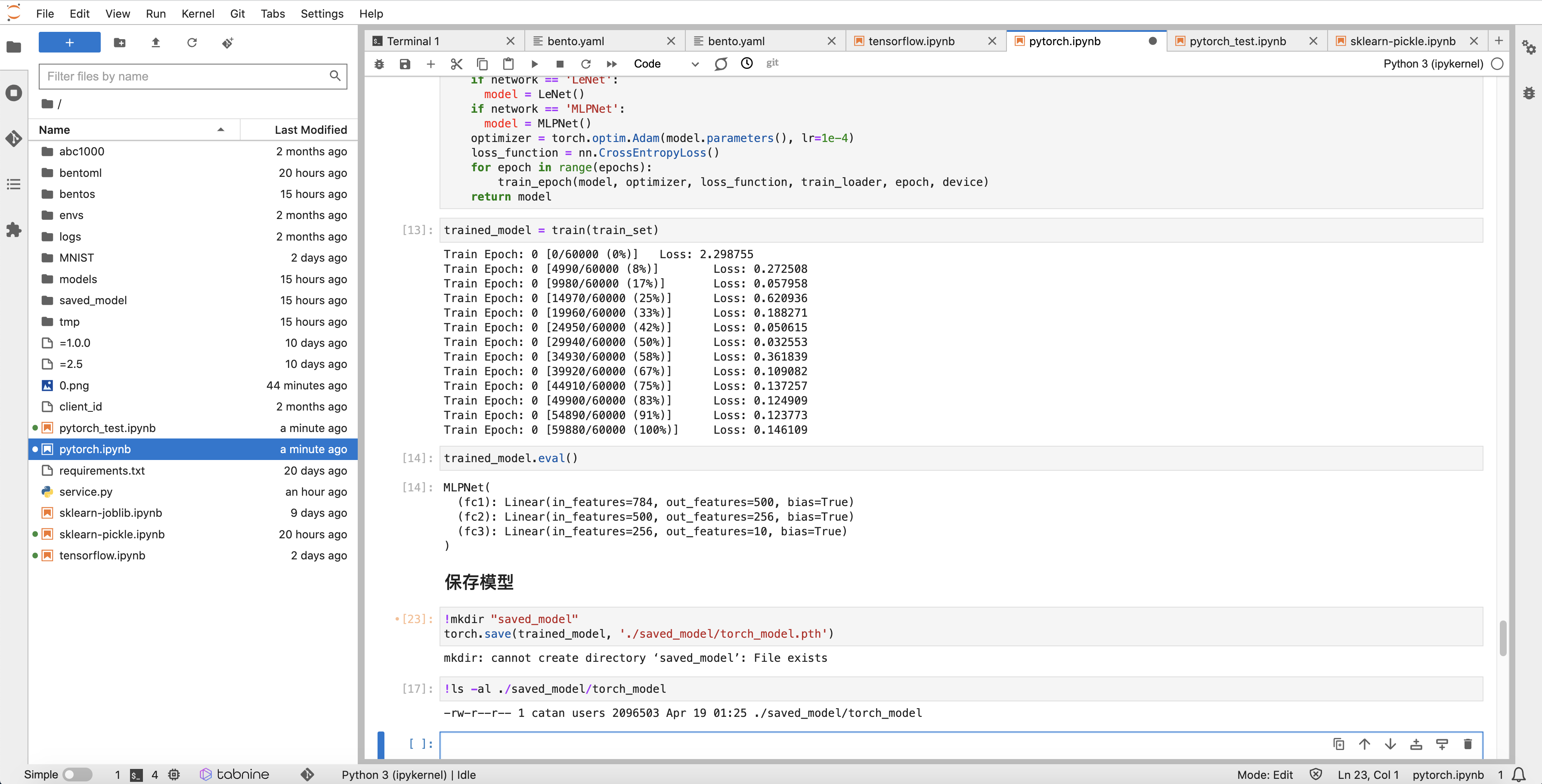
模型评估后使用 Pytorch 原生 save 方式进行打包,其中 FilePath 为模型存储文件,文件扩展名为:.pt 或 .pth:
FilePath = './saved_model/torch_model.pth'
torch.save(model, f'{FilePath}')
提示
如果您使用的是自定义模型网络,请将网络定义文件也一并保存在 FilePath 的 同级目录 中
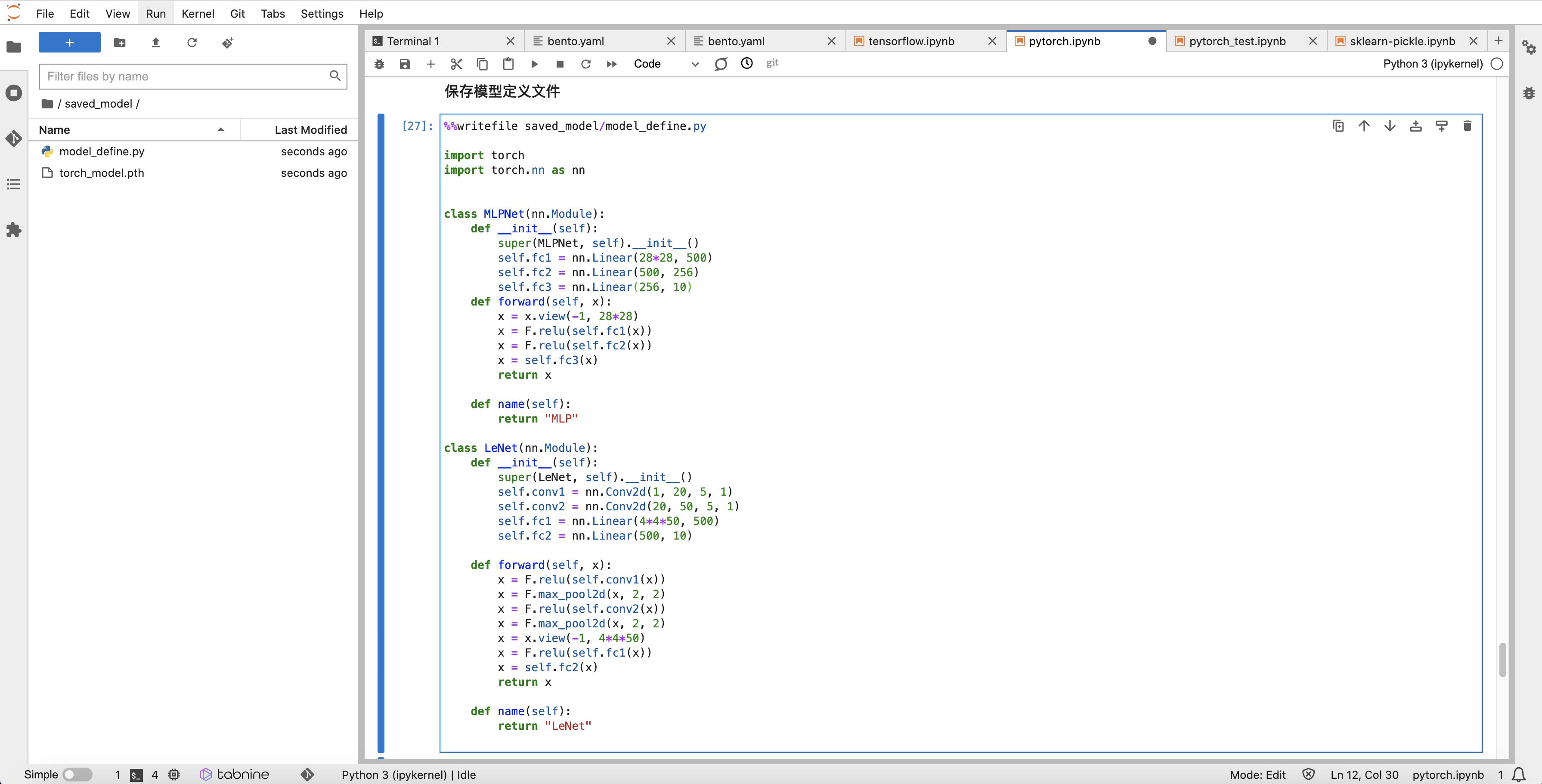
创建构建
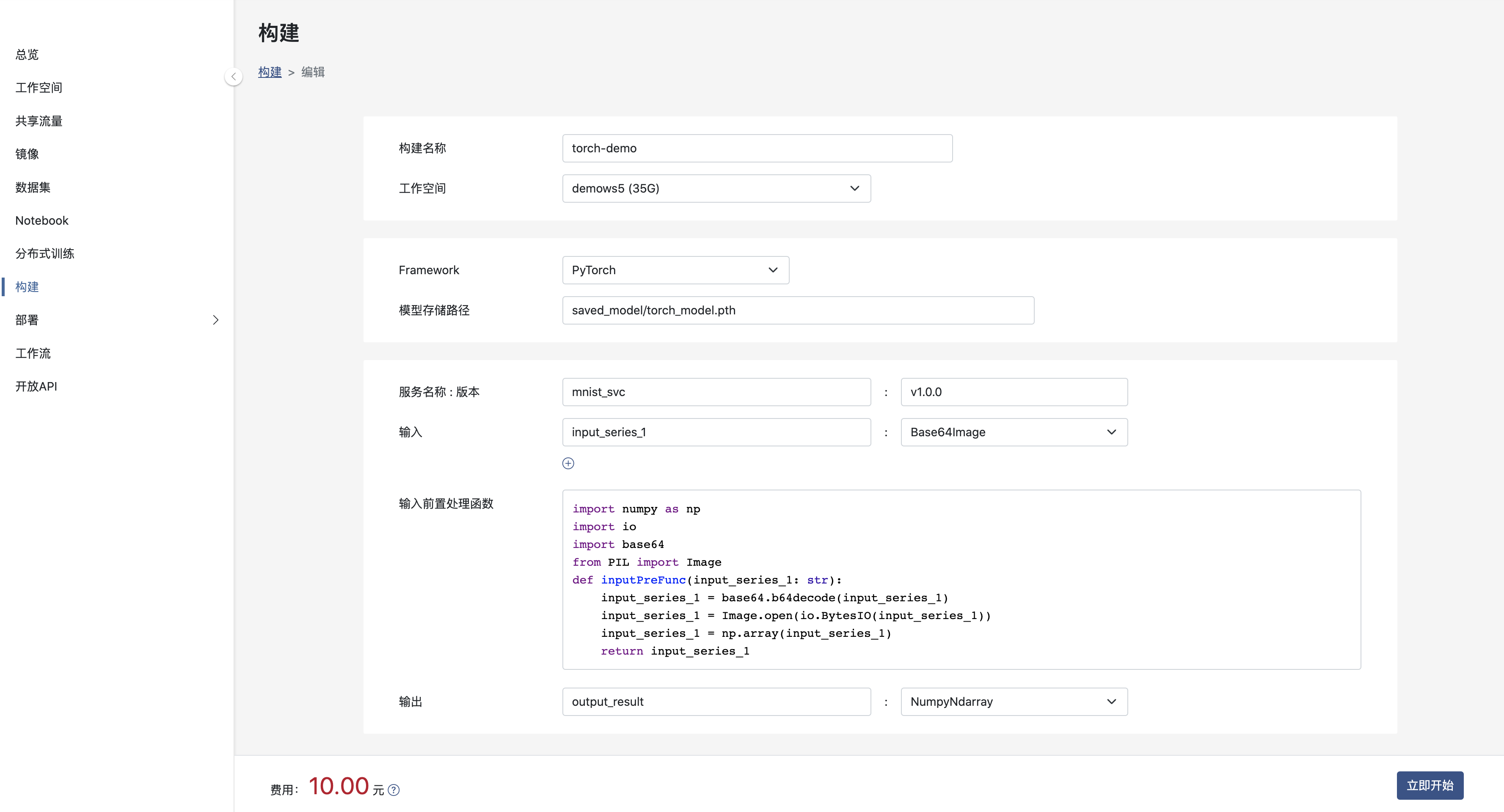
其中:
- 工作空间: 模型所在的工作空间。
- Framework: 模型所使用的框架。
- 模型存储路径: 模型打包文件存储路径, 上例模型存储路径为 models/iris_clf.pkl。
- 服务名和版本: 将模型打包为服务,该模型的服务名称与版本号,服务名及版本号在租户内唯一。
- 输入和输出: 模型数输入和输出名称和类型,目前, 输入参数可选择 Base64Image 和 NumpyNdarray 两种类型,输出结果类型仅可以为NumpyNdarray。
- 输入前置处理函数: 如果模型的输入需要根据自身业务进行一定的处理,则请将处理内容加入到函数中。如果您不提供相应的处理,系统将提供默认行为。
提示
请注意:对于 Pytorch 模型路径,请一定输入模型文件完整路径,且自定义网络文件与该模型文件在同一目录下,并保证该路径下没有其他干扰文件
提示
请注意:由于当前mnist手写体识别例子中模型使用图片作为输入,构建中请选择输入类型为 Base64Image
当输入类型为 Base64Image 时,输入前置处理函数 内容将自动加入处理代码。
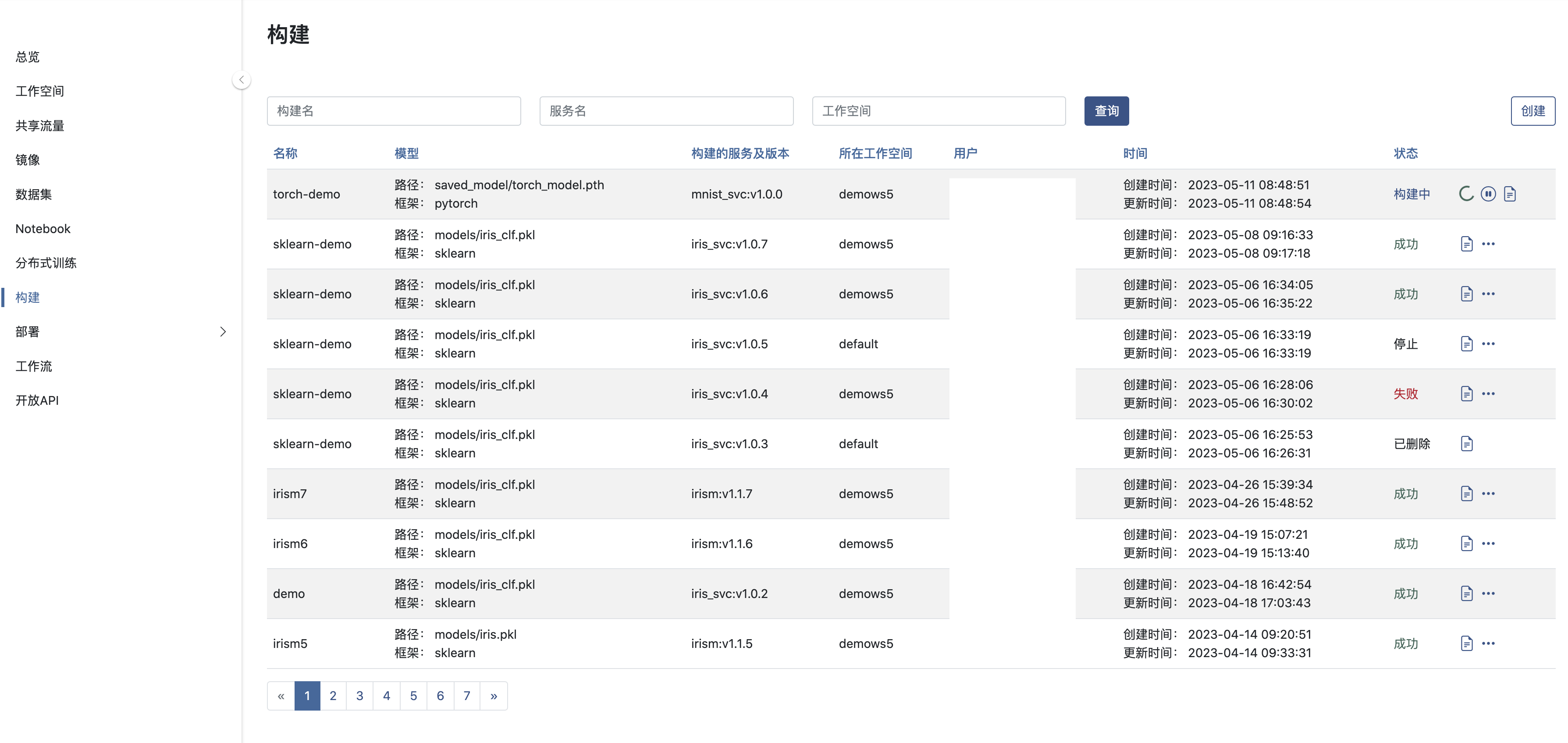
构建提交
提交构建后,AILines将在后台将模型打包成服务, 一般需要等待5~10分钟,如果模型的复杂度高并且 Python 依赖多则等待时间会有所延长。
提示
关于如何部署,请参看:模型部署
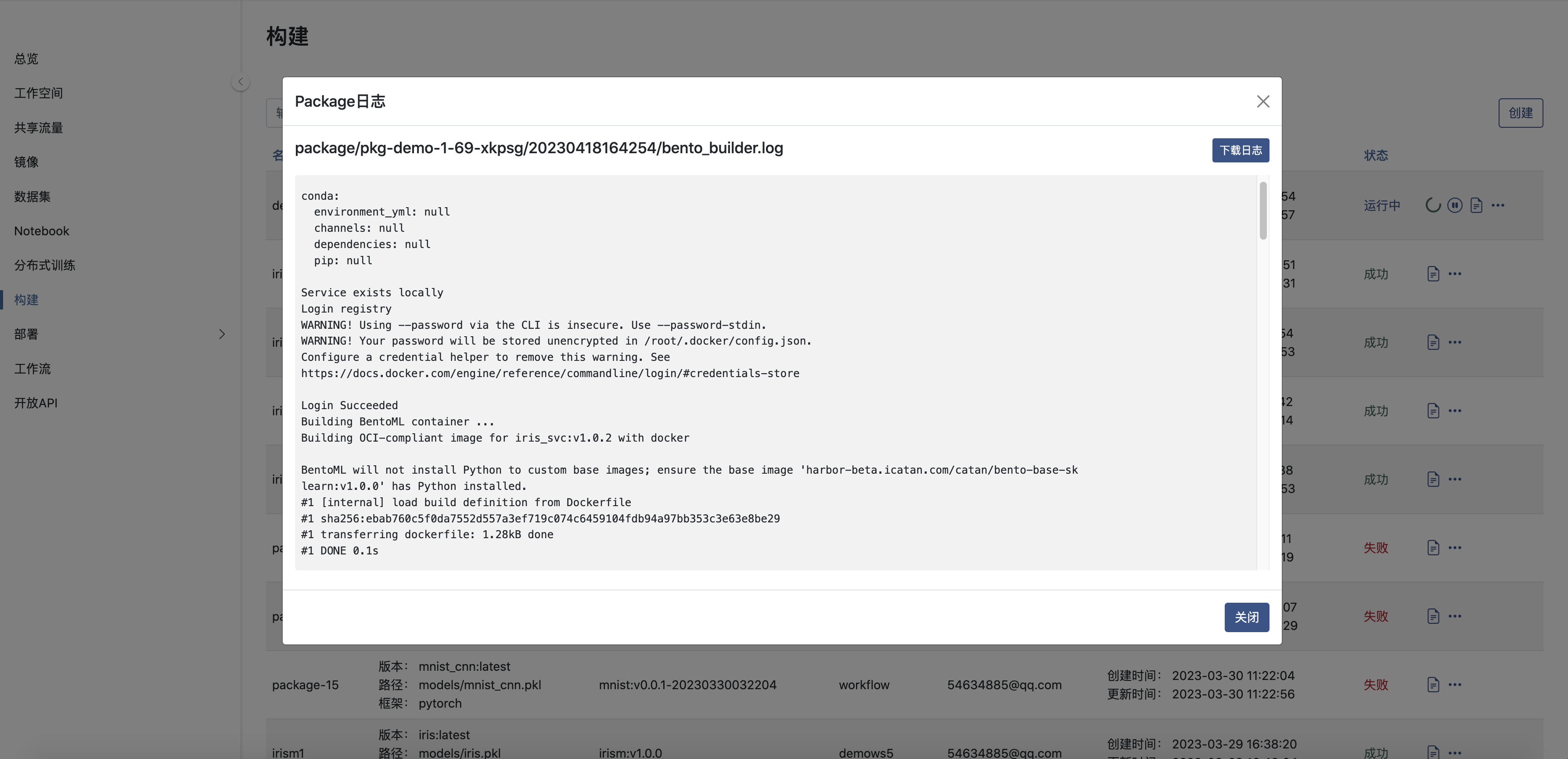
查看日志
Pytorch参考代码
模型网络定义
import torch
import torch.nn as nn
import torch.nn.functional as F
# 多层感知机
class MLPNet(nn.Module):
def __init__(self):
super(MLPNet, self).__init__()
self.fc1 = nn.Linear(28*28, 500)
self.fc2 = nn.Linear(500, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def name(self):
return "MLP"
# 卷积神经网络
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def name(self):
return "LeNet"
数据加载器定义
import os
import random
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, ConcatDataset
from torchvision import transforms
from sklearn.model_selection import KFold
# reproducible setup for testing
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def _dataloader_init_fn(worker_id):
np.random.seed(seed)
数据集拆分、训练纪元、模型验证定义
K_FOLDS = 5
NUM_EPOCHS = 1
LOSS_FUNCTION = nn.CrossEntropyLoss()
def get_dataset():
# Prepare MNIST dataset by concatenating Train/Test part; we split later.
train_set = MNIST(
os.getcwd(), download=True, transform=transforms.ToTensor(), train=True
)
test_set = MNIST(
os.getcwd(), download=True, transform=transforms.ToTensor(), train=False
)
return train_set, test_set
def train_epoch(model, optimizer, loss_function, train_loader, epoch, device="cpu"):
# Mark training flag
model.train()
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
if batch_idx % 499 == 0:
print(
"Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch,
batch_idx * len(inputs),
len(train_loader.dataset),
100.0 * batch_idx / len(train_loader),
loss.item(),
)
)
def test_model(model, test_loader, device="cpu"):
correct, total = 0, 0
model.eval()
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
return correct, total
训练
network = "MLPNet"
def train(dataset, epochs=NUM_EPOCHS, device="cpu"):
train_sampler = torch.utils.data.RandomSampler(dataset)
train_loader = torch.utils.data.DataLoader(
dataset,
batch_size=10,
sampler=train_sampler,
worker_init_fn=_dataloader_init_fn,
)
model = None
if network == 'LeNet':
model = LeNet()
if network == 'MLPNet':
model = MLPNet()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_function = nn.CrossEntropyLoss()
for epoch in range(epochs):
train_epoch(model, optimizer, loss_function, train_loader, epoch, device)
return model
# 使用GPU
DEVICE = "cuda"
# dataset
train_set, test_set = get_dataset()
# train
trained_model = train(train_set, NUM_EPOCHS, DEVICE)
验证
# test
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=10,
sampler=torch.utils.data.RandomSampler(test_set),
worker_init_fn=_dataloader_init_fn,
)
test_model(trained_model, test_loader, DEVICE)
存储模型
import os
model_path = "./saved_model"
if not os.path.exists(model_path):
os.makedirs(model_path)
torch.save(trained_model, model_path + '/torch_model.pth')