工作流引擎的使用
本节通过几个具体的示例来说明AI工作流使用的基本范式。
工作流基本操作
新增
点击+添加工作流

输入名称和描述
编辑、保存、发布
- 点击+可添加节点
- 节点可以通过线连通
- 点击对应节点会从右侧弹出编辑面板,对节点进行配置
- 可以通过拖拽的方式调整布局
- 可以放大或缩小视图
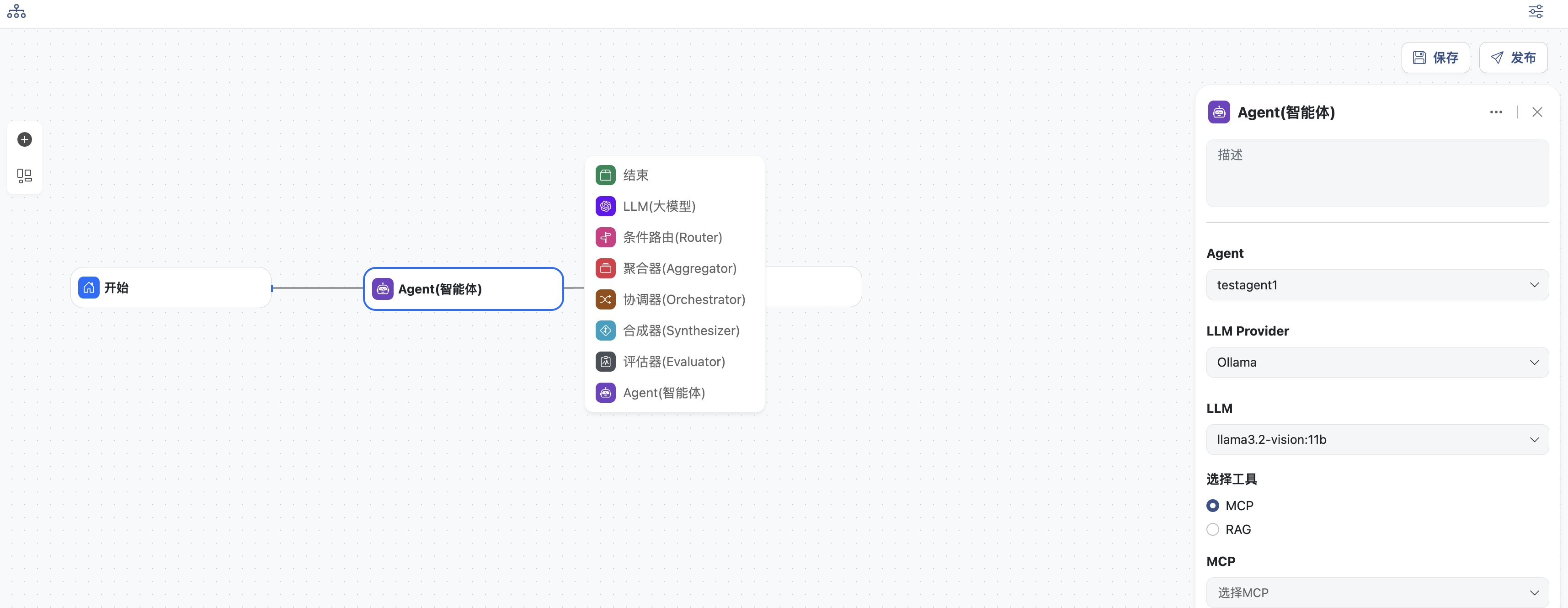
- 点击右上角保存按钮,将保存改动
- 点击发布按钮,将生成可执行的工作流程序,并生成历史
修改、打标签
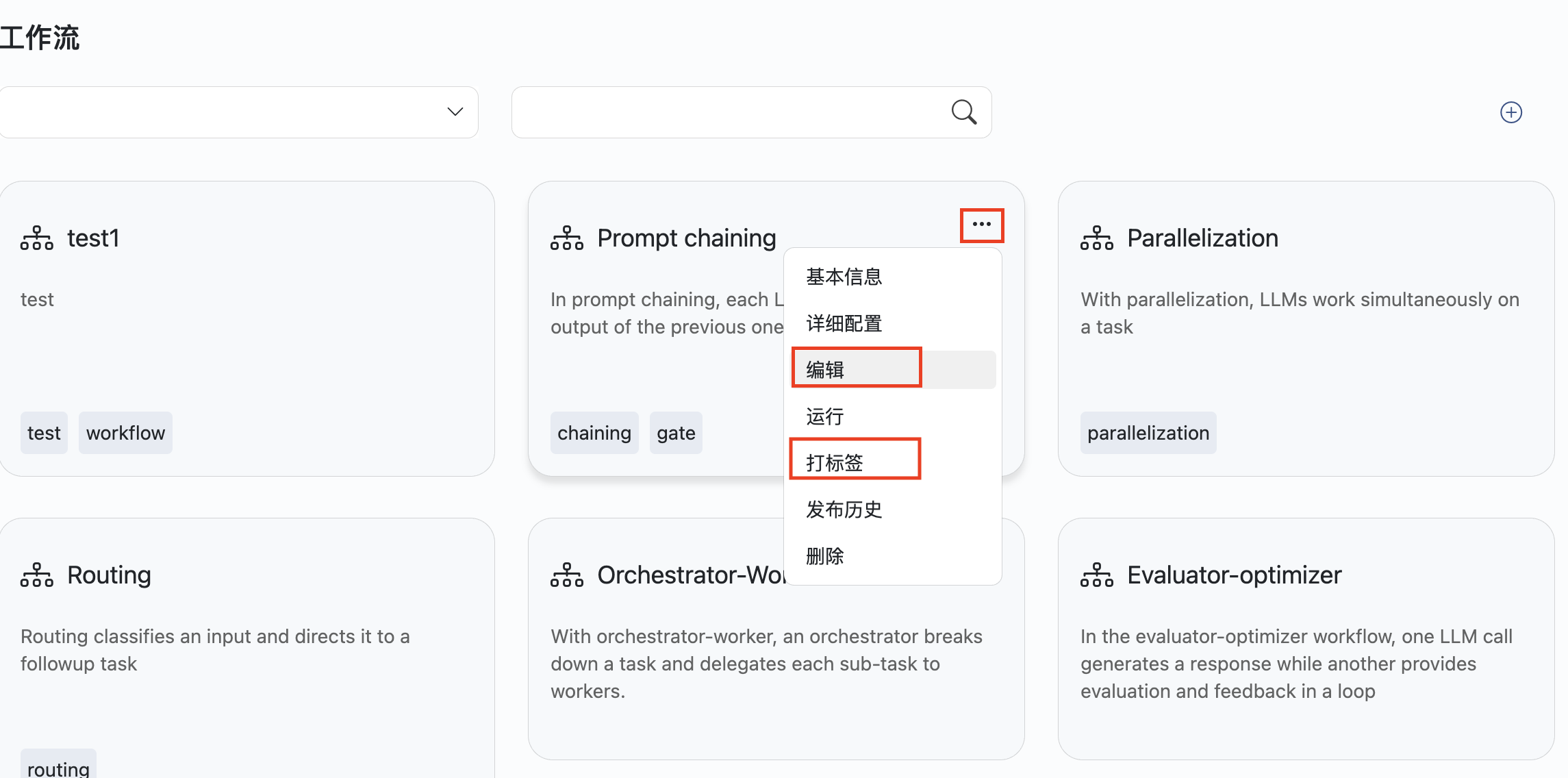
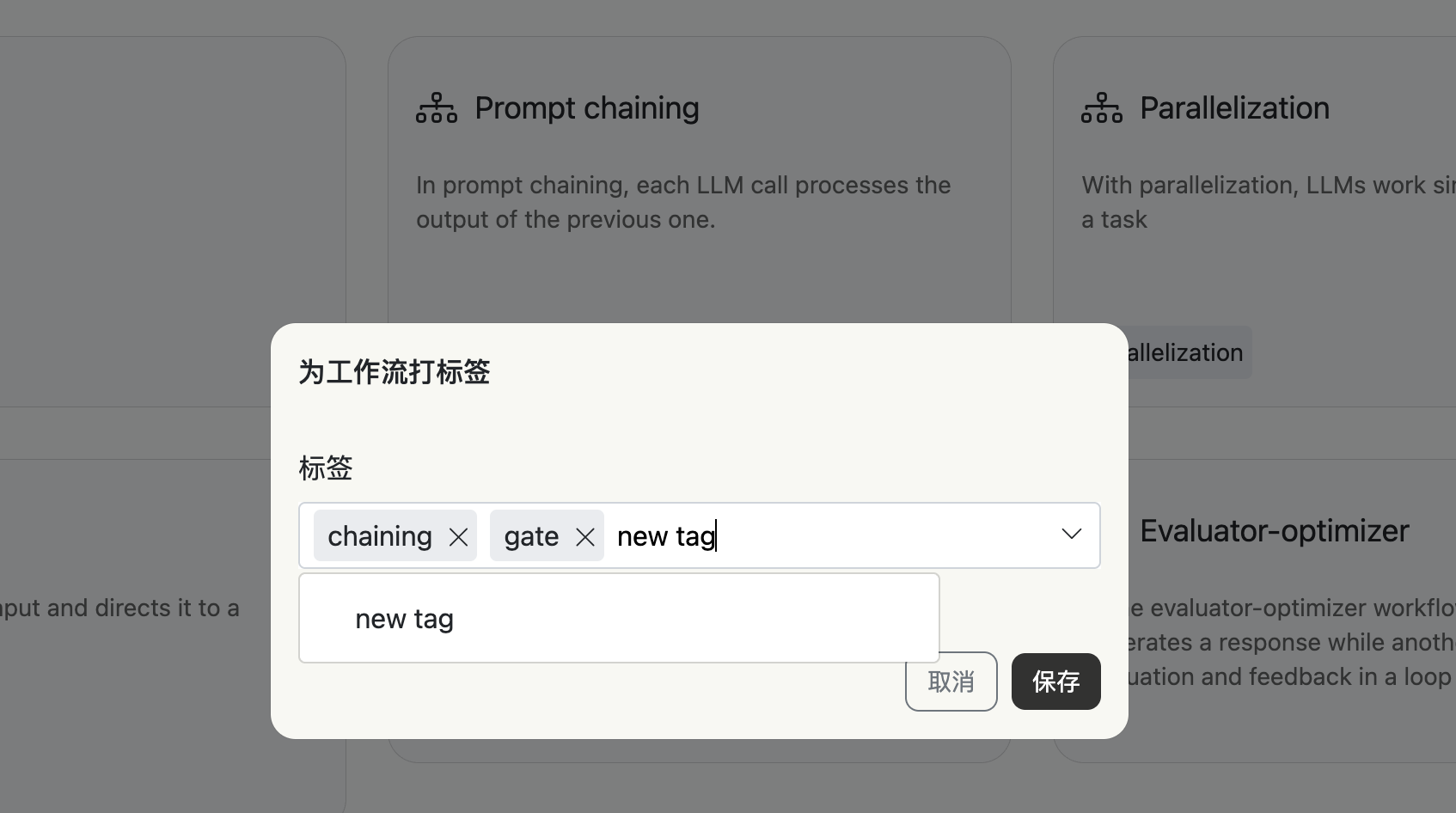
运行
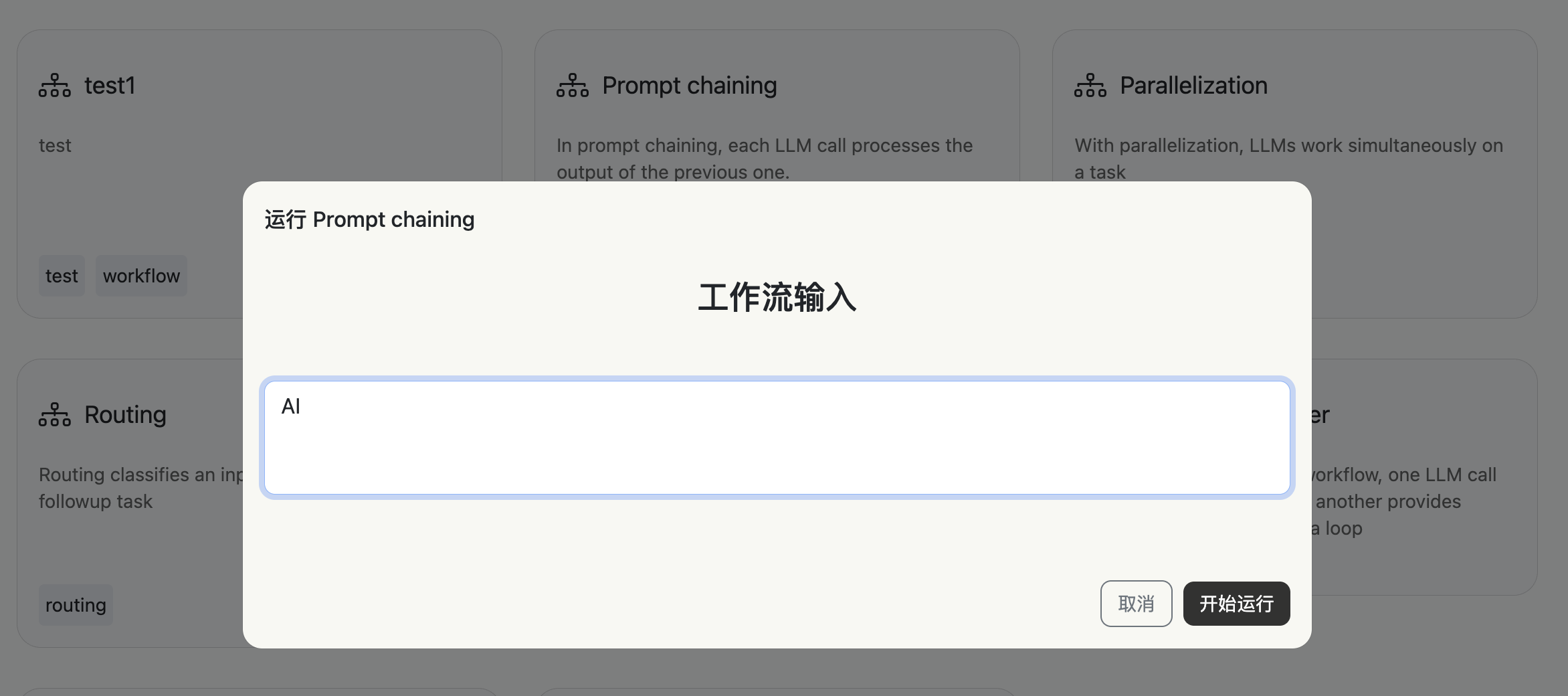
点击工作流上...,在下拉菜单中点击运行。
输入内容:
工作流开始运行,绿色边框节点表示已经成功运行完成,蓝色边框节点表示正在运行
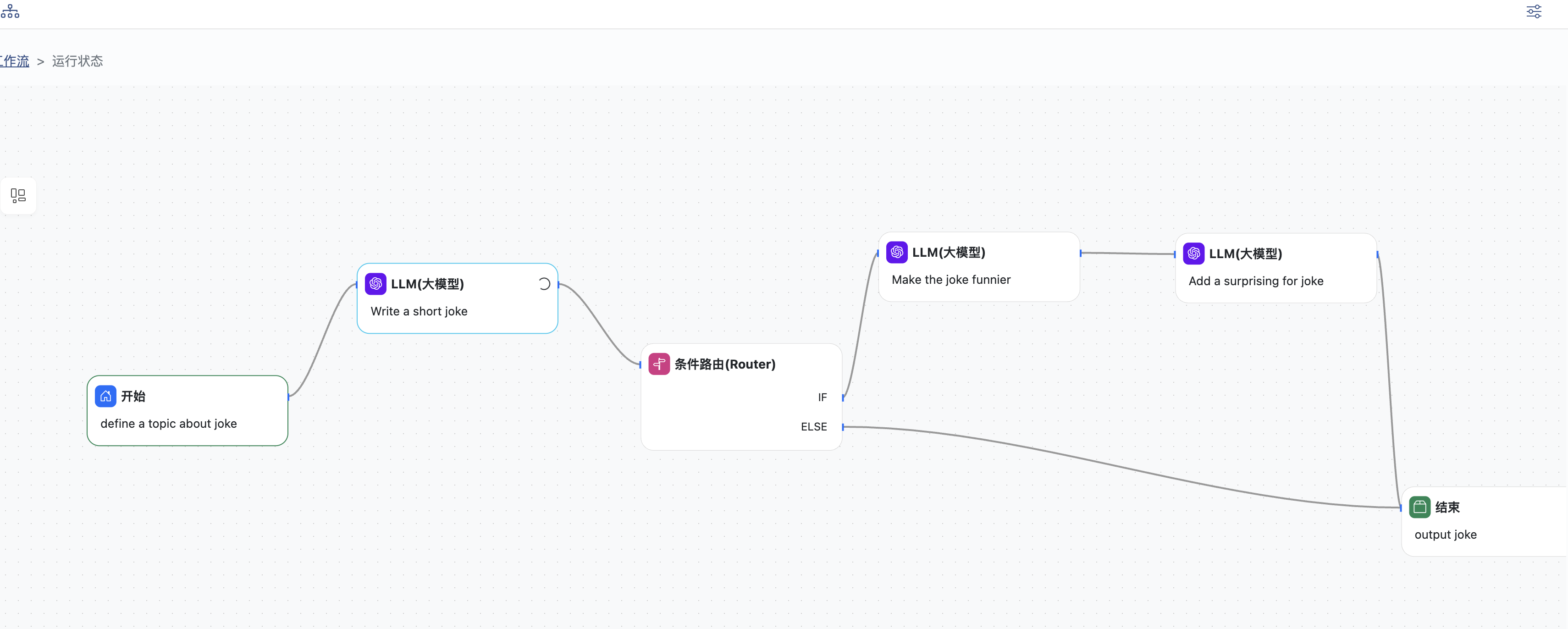
点击任意节点可以查看运行日志
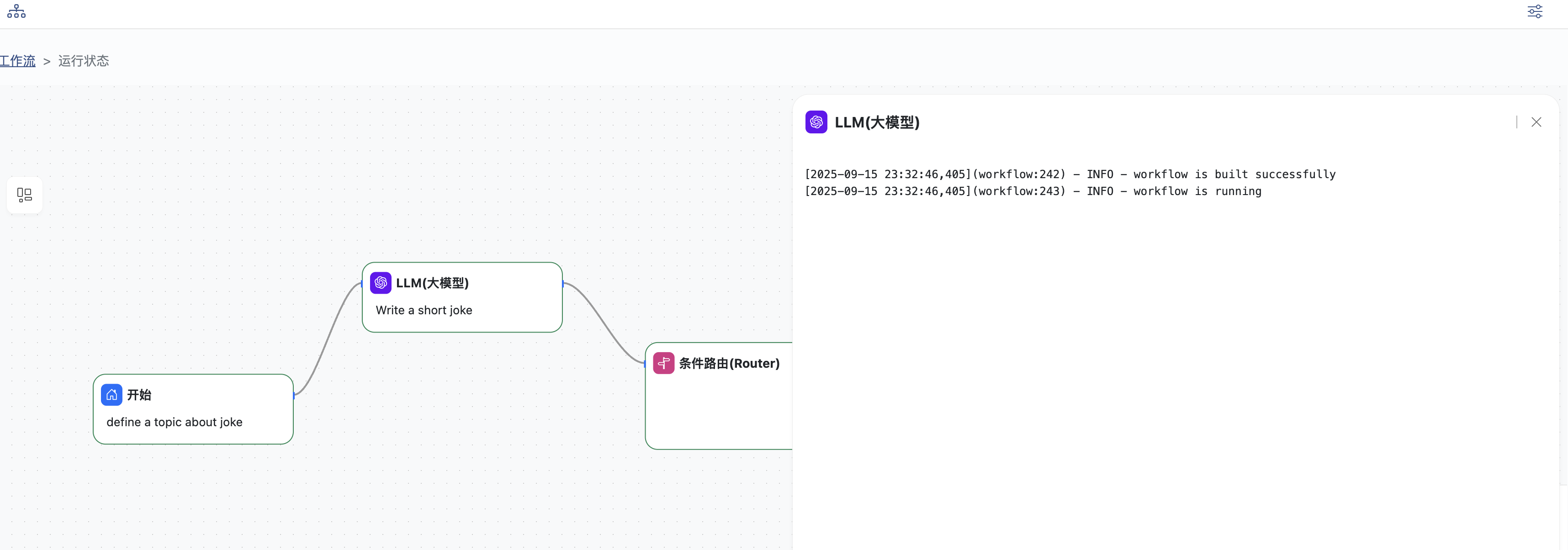
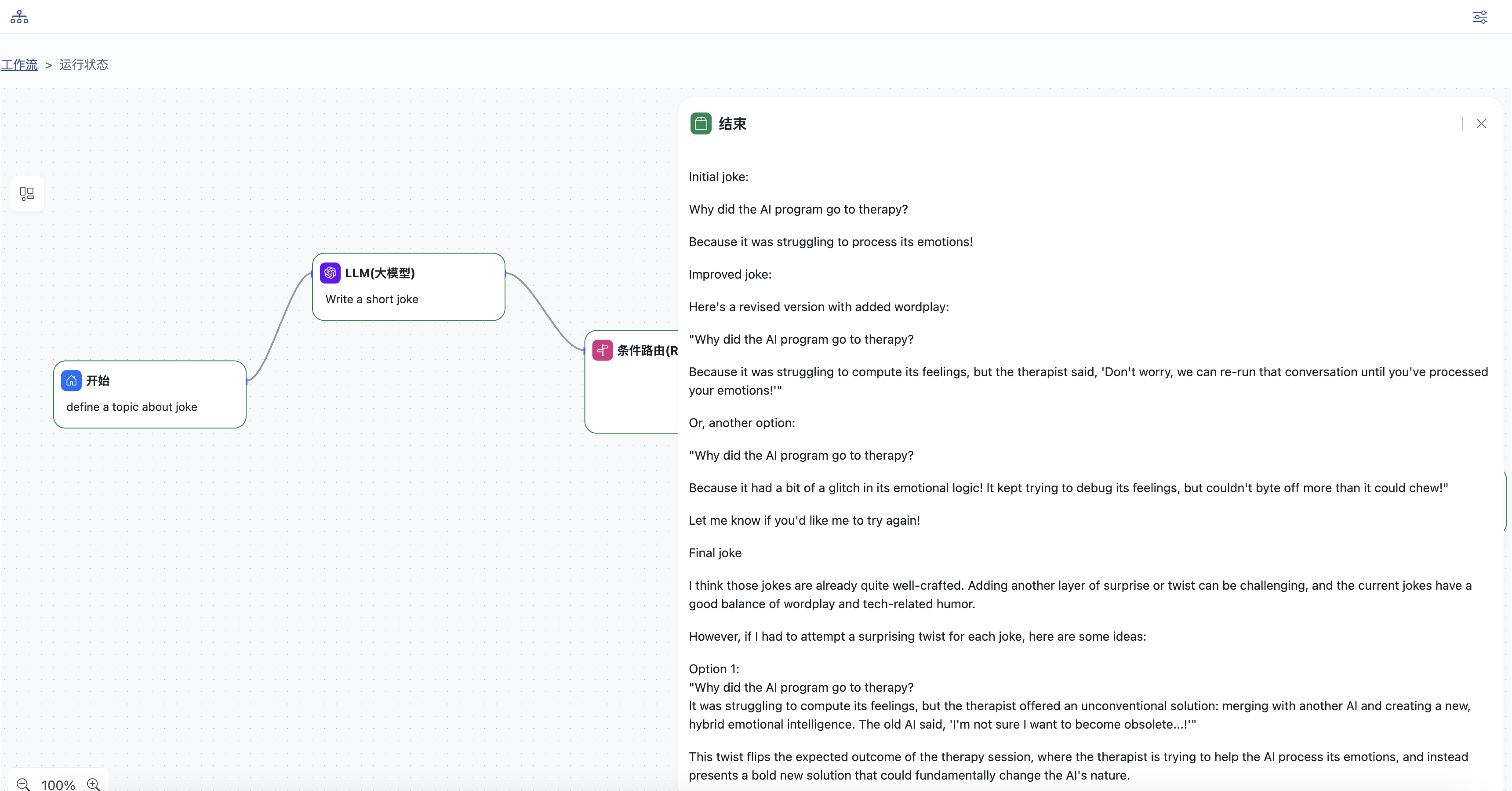
点击结束节点可以查看输出结果
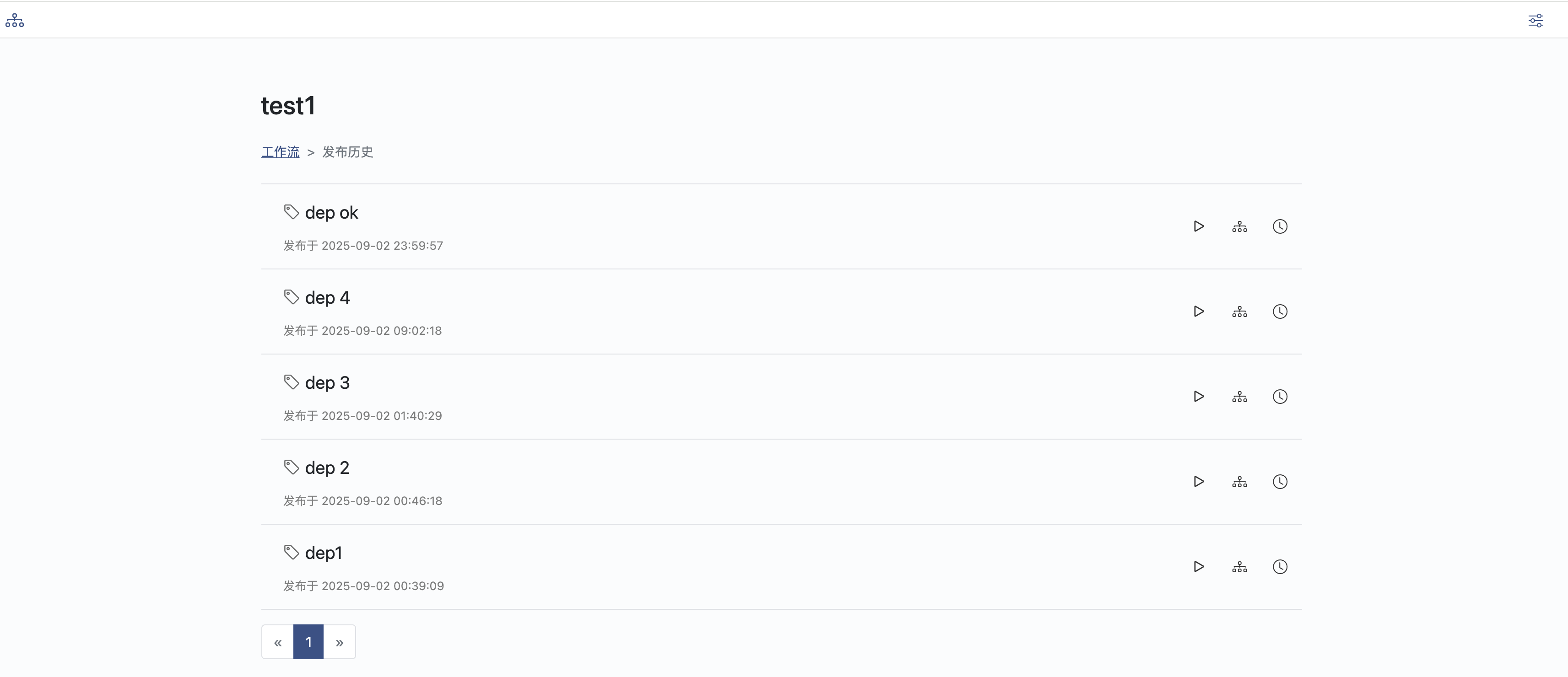
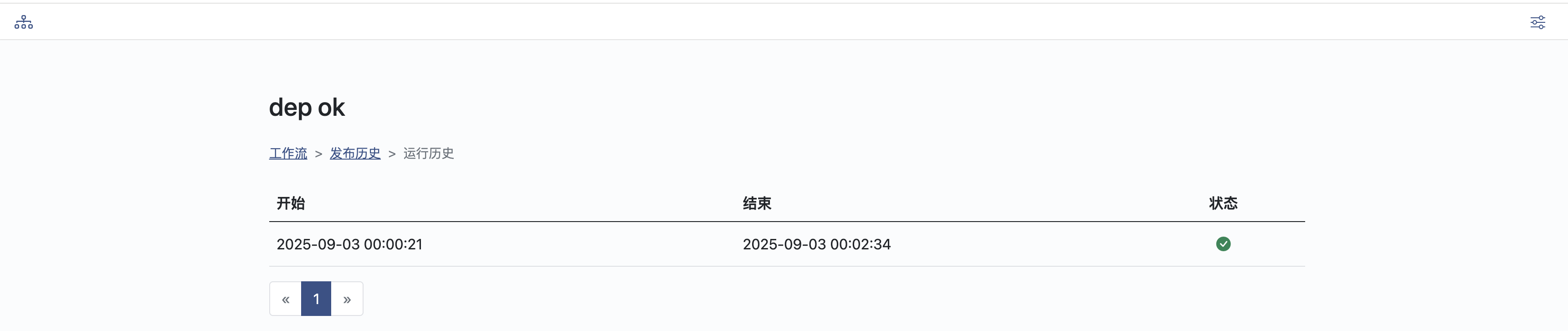
查看发布、运行历史以及结果
查询
可以选择标签或者输入关键字查询工作流
配置LLM
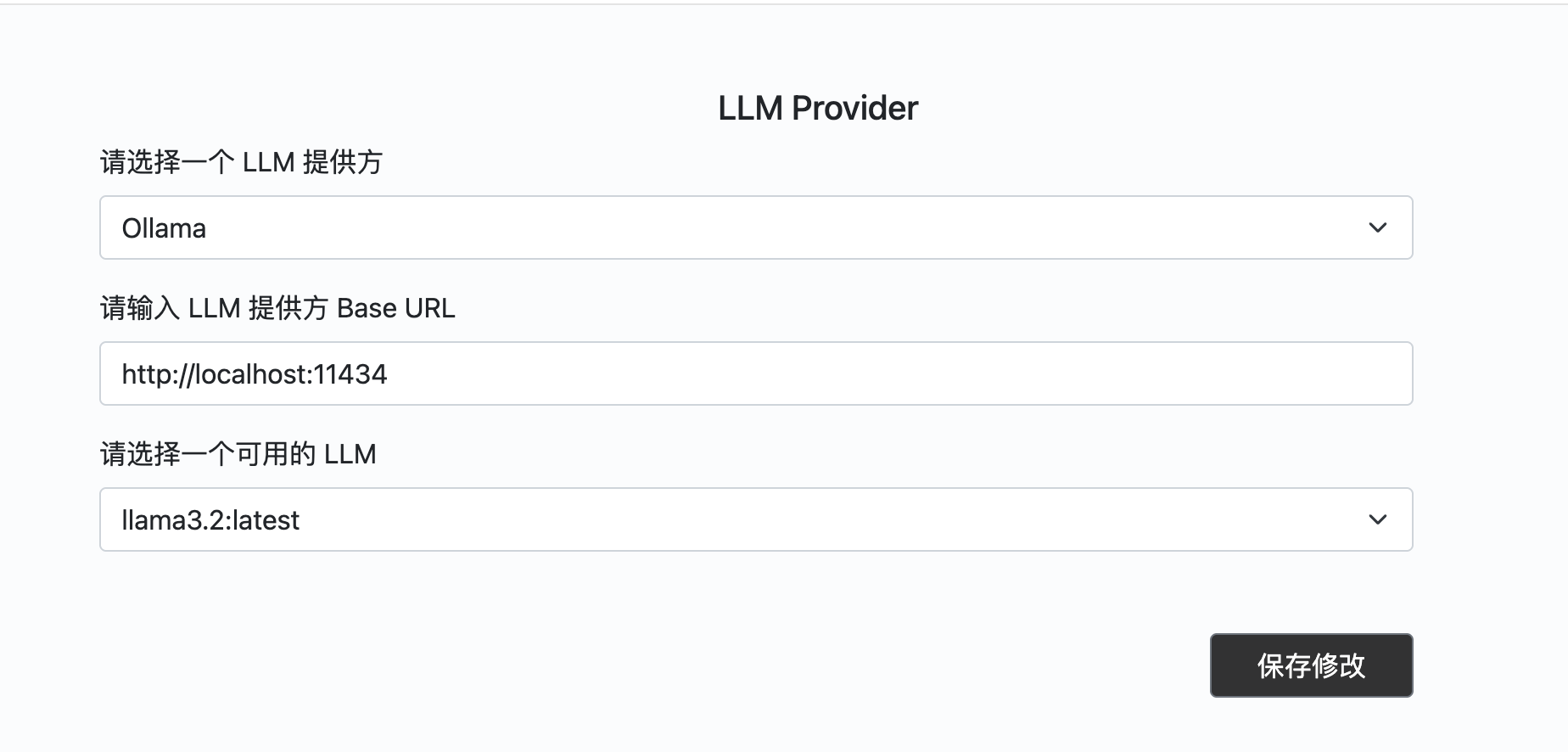
点击页面右上角设置按钮

选择LLM提供者,从备选模型中选择一个保存
工作流使用示例
提示链模式
提示链将任务分解为一系列步骤,其中每个 LLM 调用都会处理前一个步骤的输出。
您可以在任何中间步骤上添加程序化检查,以确保流程仍在正常进行。
什么情况下使用此类型工作流程:此工作流程非常适合任务可以轻松清晰地分解为固定子任务的情况。其主要目标是通过简化每个 LLM 调用来降低延迟,从而提高准确率。
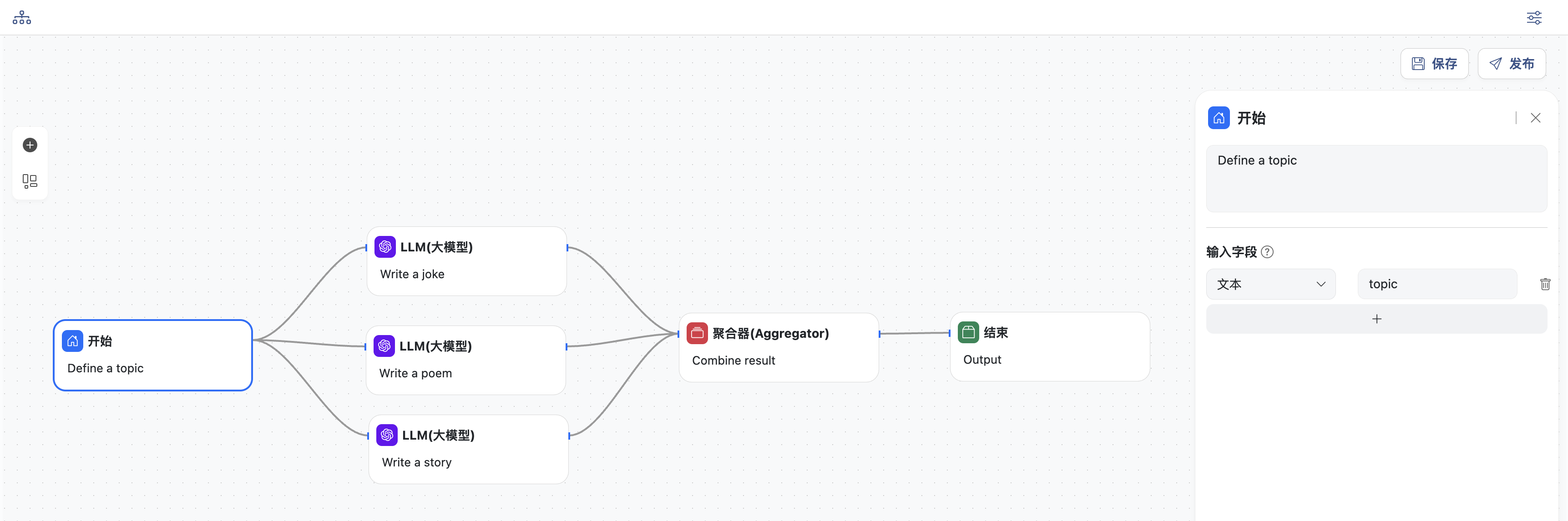
- 开始节点,定义工作流的主题,变量名为:
topic,这里是关于一则笑话的主题
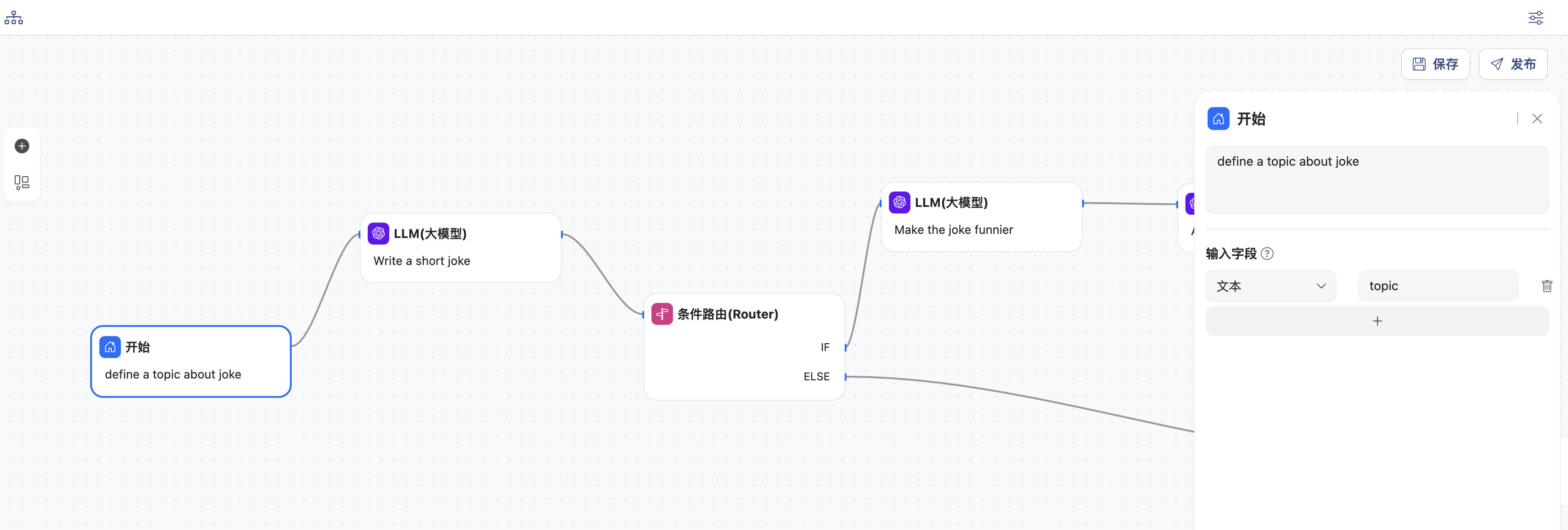
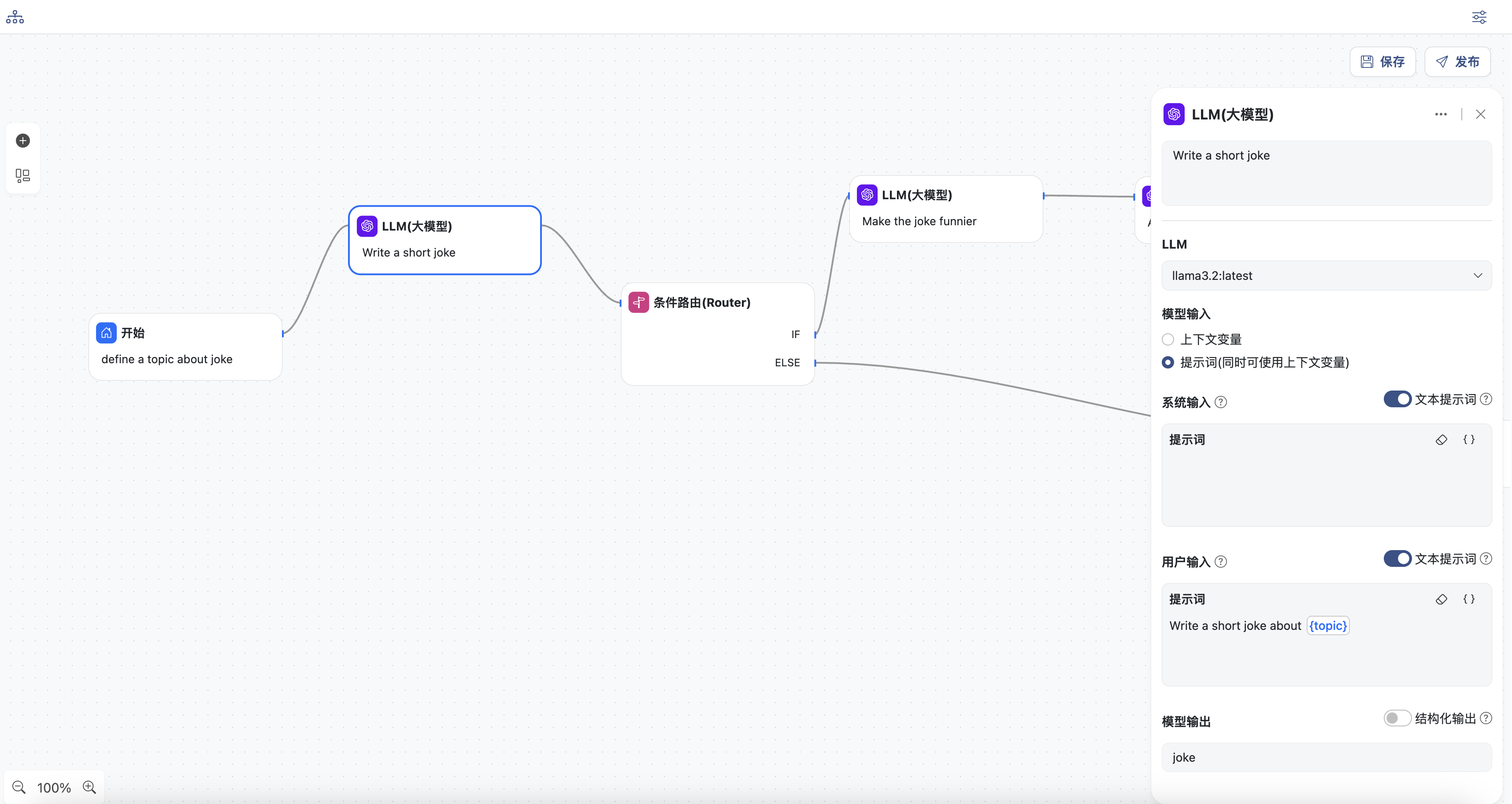
- LLM节点
- 选择一个模型
- 输入用户提示词,提示词中可以选择上下文中的变量,这里选择
topic - 同时定义模型输出,变量名为:
joke
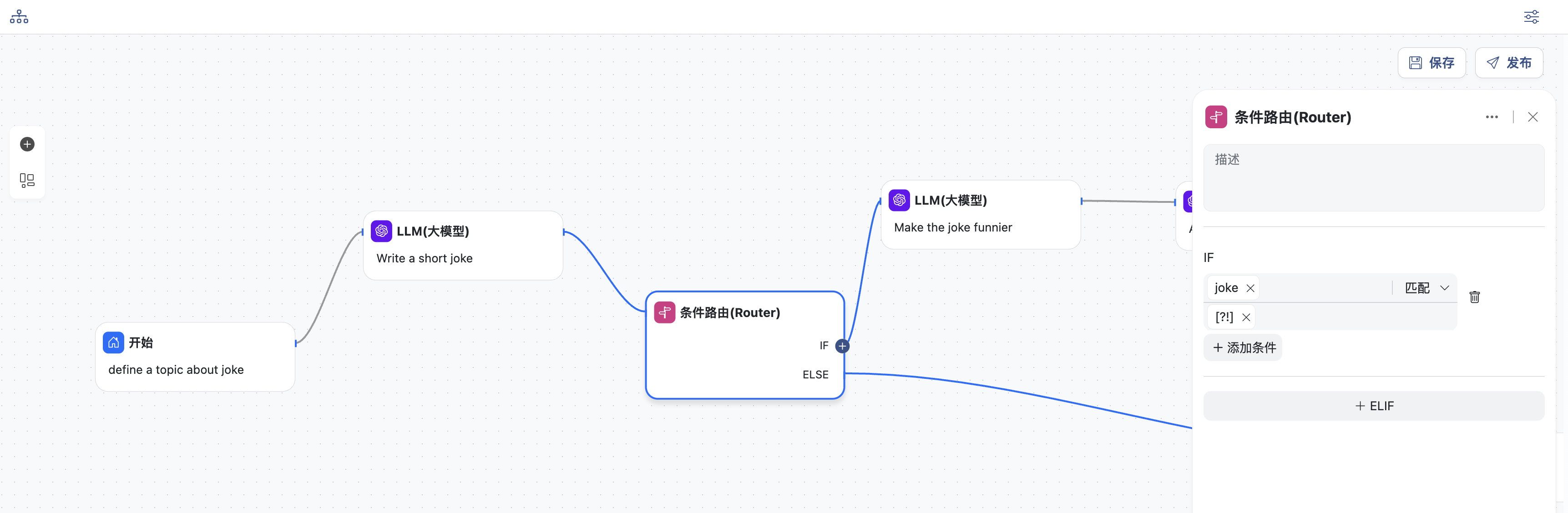
- 条件路由节点,添加一个IF条件,选择上一节点输出的变量
joke作为条件参数,条件判断选择:匹配,条件值为正则表达式:[?!],
含义是:输入的笑话中包含问号或者叹号
- 满足此条件就会进入下一个LLM节点
- 否则进入结束节点,直接退出
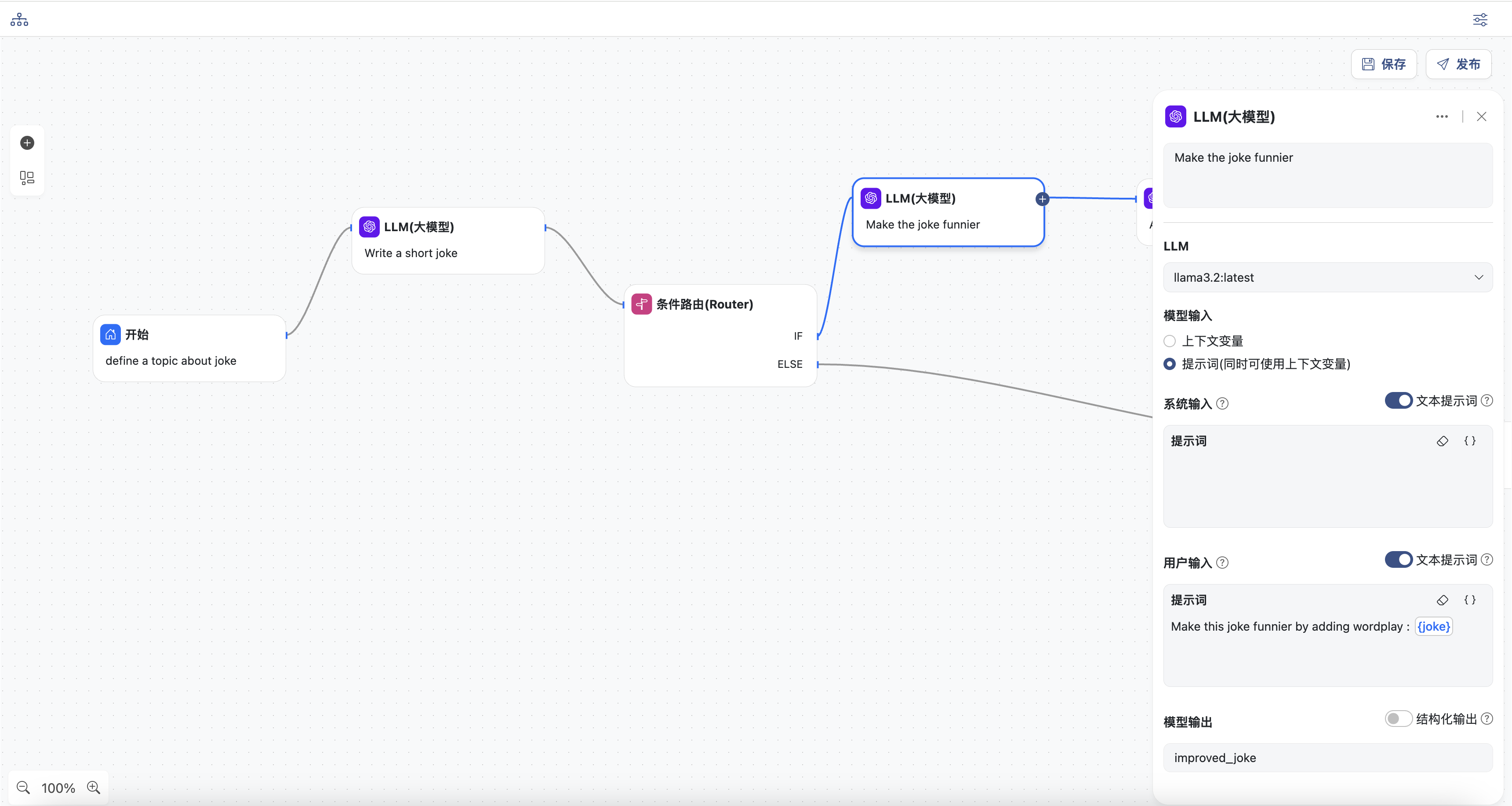
- LLM节点,根据前续节点输出的
joke,重新生成,使笑话更有趣。
- 选择一个模型
- 输入用户提示词,提示词中可以选择上下文中的变量,这里选择
joke - 同时定义模型输出,变量名为:
improved_joke
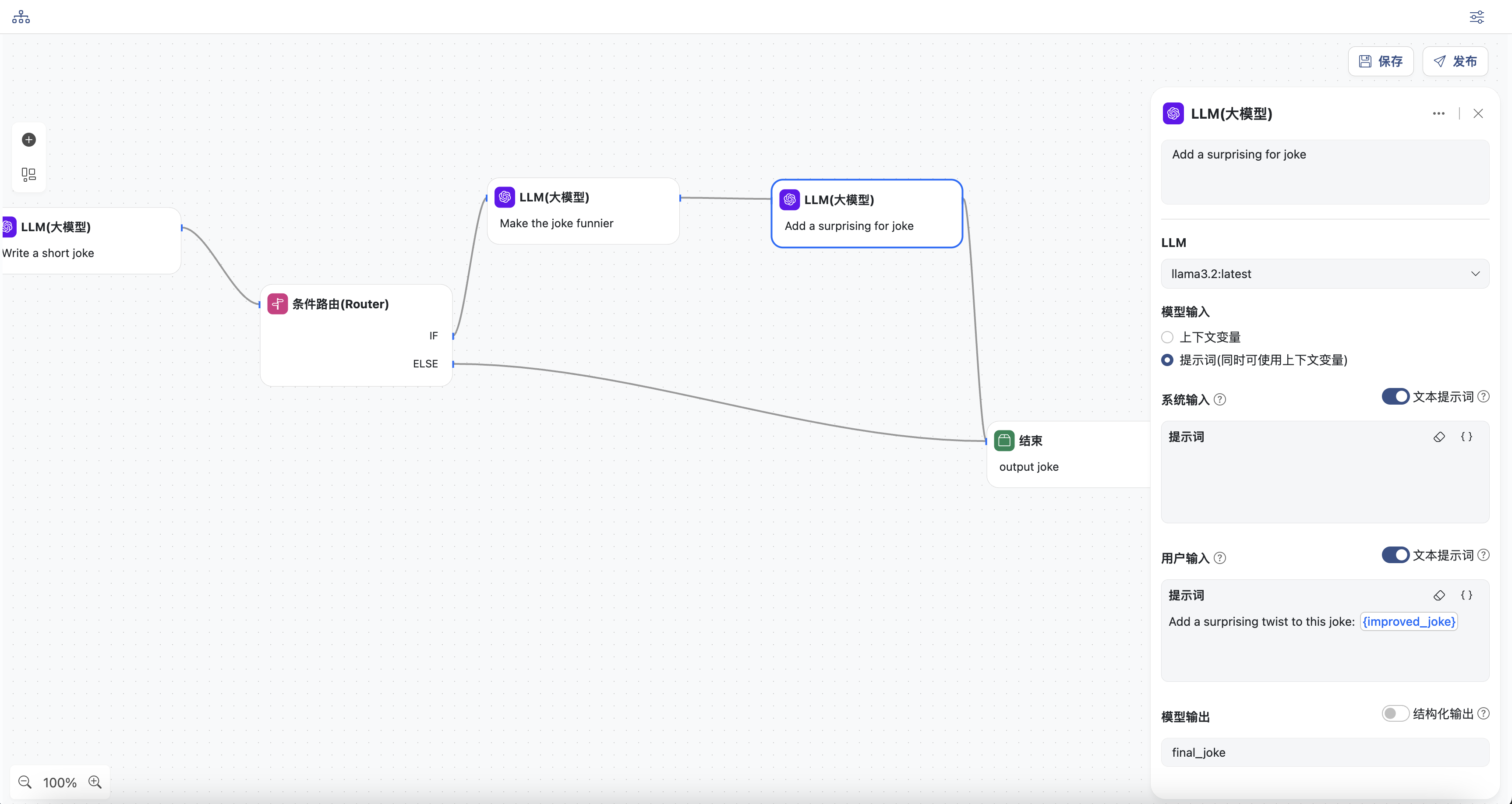
- LLM节点,根据前续节点输出的
improved_joke,给笑话添加一些转折点。
- 选择一个模型
- 输入用户提示词,提示词中可以选择上下文中的变量,这里选择
improved_joke - 同时定义模型输出,变量名为:
final_joke
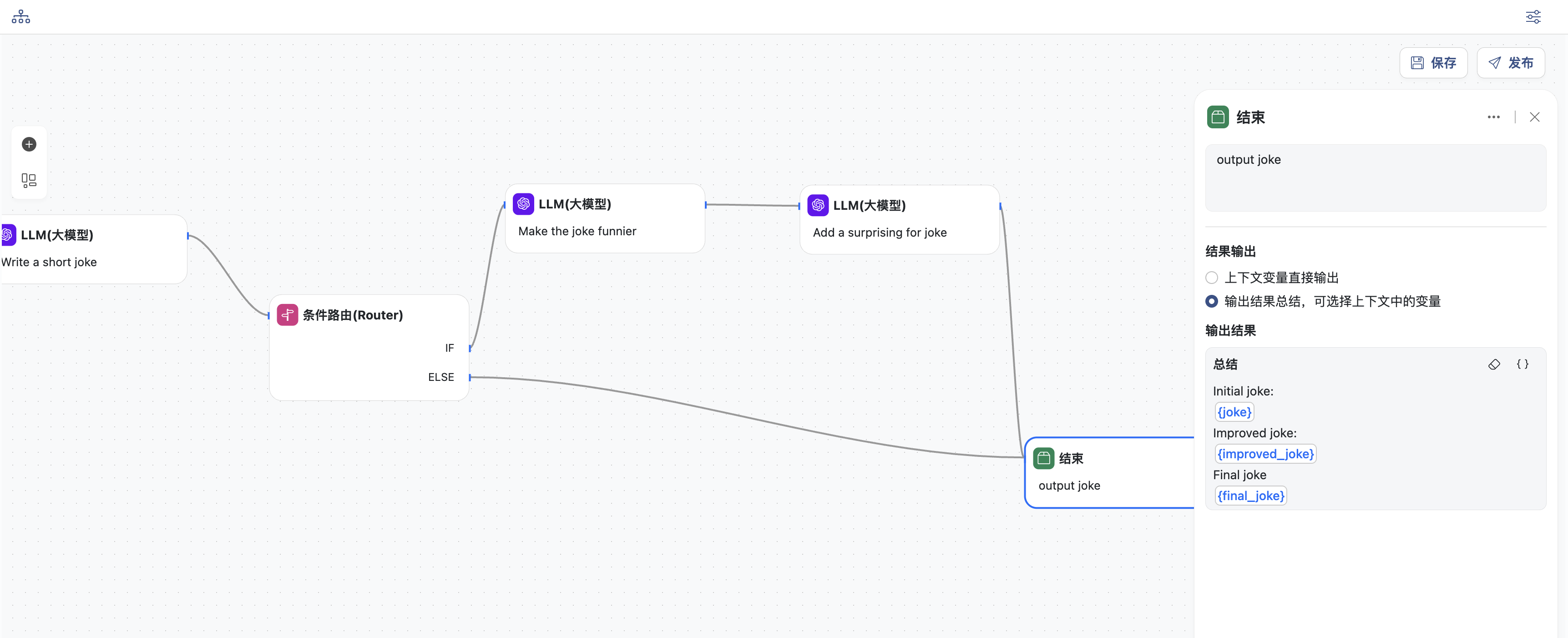
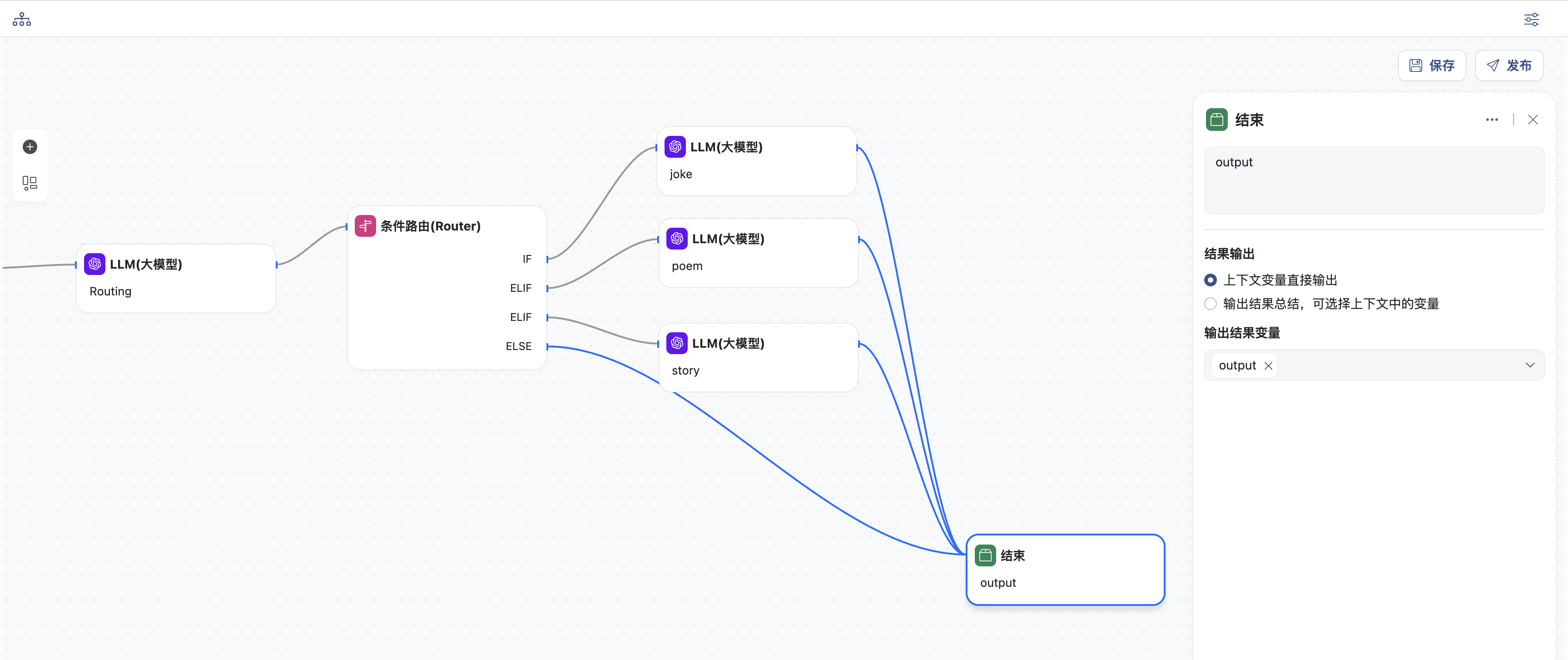
- 结束节点,输出结果
- 选择输出结果总结模式
- 定义总结,选择上下文中的变量
joke,improved_joke,final_joke
并行模式
LLM 有时可以同时处理一项任务,并以编程方式汇总其输出。
这种工作流程,即并行化,体现在两个关键方面:
- 分段:将任务分解为并行运行的独立子任务。
- 投票:多次运行同一任务以获得不同的输出。
什么情况下使用此类型工作流程:当划分的子任务可以并行化以提高速度,或者当需要多个视角或尝试以获得更高置信度的结果时,并行化非常有效。
对于包含多个考量的复杂任务,当每个考量都由单独的 LLM 调用处理时,LLM 通常表现更佳,从而能够专注于每个特定方面。
- 开始节点,定义工作流的主题,变量名为:
topic,这里是关于笑话、诗歌、故事的主题
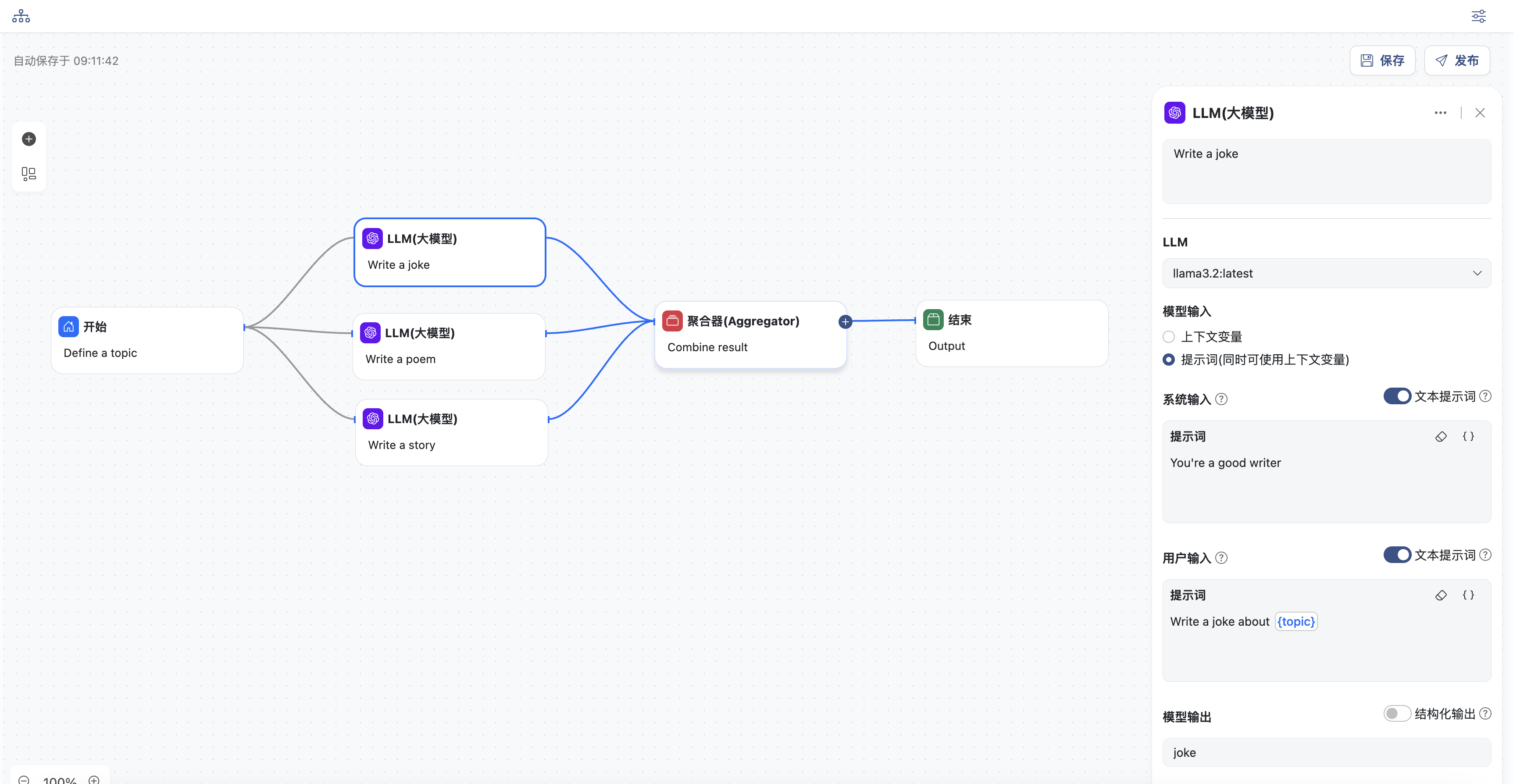
- 三个并行的LLM节点,分别生成笑话、诗歌和故事。分别配置各个节点:
- 选择一个模型
- 输入系统提示词和用户提示词,提示词中可以选择上下文中的变量,这里选择
topic - 同时定义模型输出,三个节点的变量名分别为:
joke,poem,story
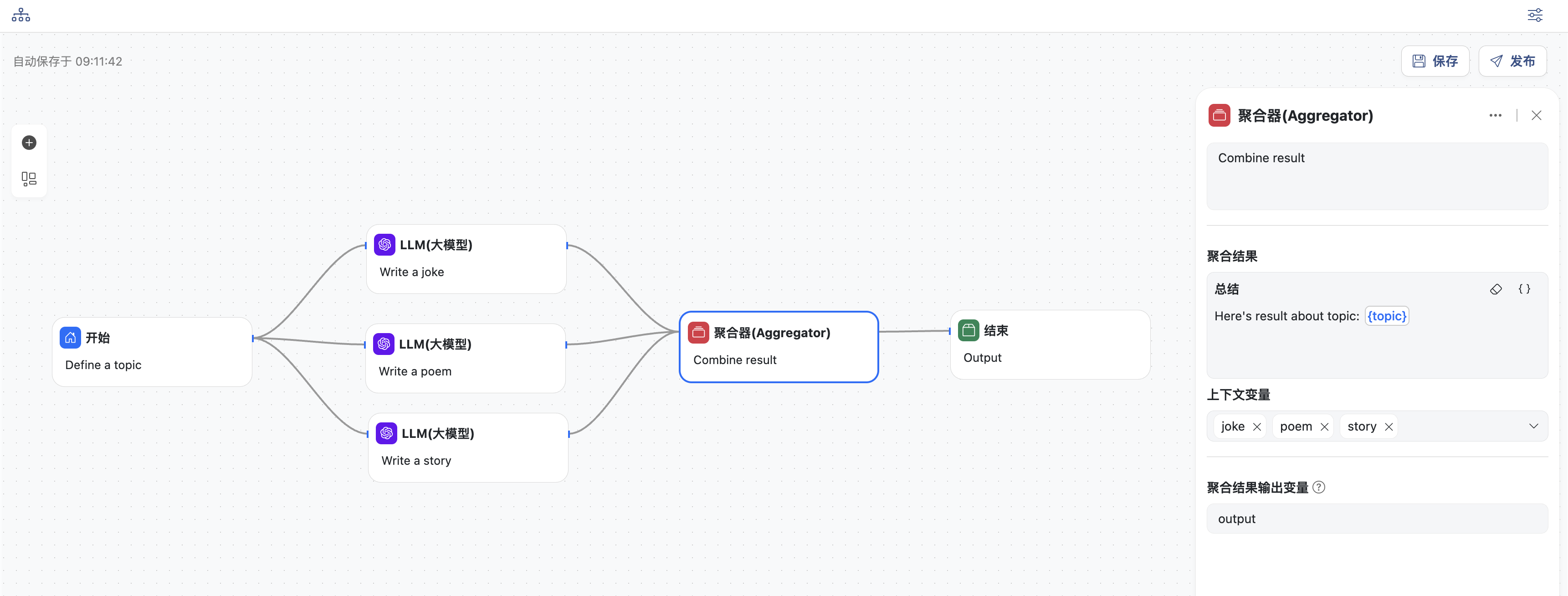
- 聚合节点,可将并行节点的输出合并总结
- 输入聚合结果总结,可以选择上下文变量,这里选择
topic - 需要聚合的上下文变量,这里选择
joke,poem,story - 同时定义聚合输出,变量名为:
output
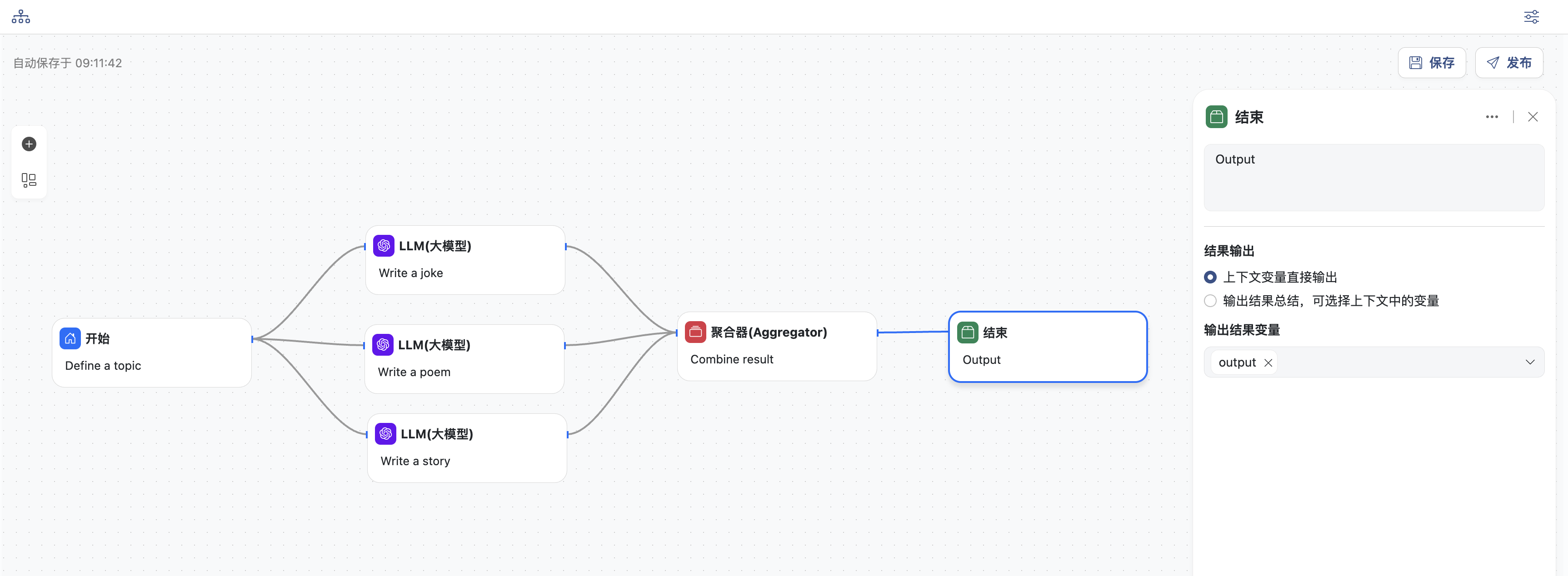
- 结束节点,输出结果
- 直接输入结果变量:
output
条件路由模式
路由会对输入进行分类,并将其定向到特定的后续任务。
此工作流程允许分离关注点,并构建更专业的提示。如果没有此工作流程,针对一种输入进行优化可能会损害其他输入的性能。
什么情况下使用此类型工作流程:路由非常适合复杂任务,这些任务包含不同的类别,最好单独处理,并且可以通过 LLM 进行准确分类。
- 开始节点,定义工作流的输入,变量名为:
input
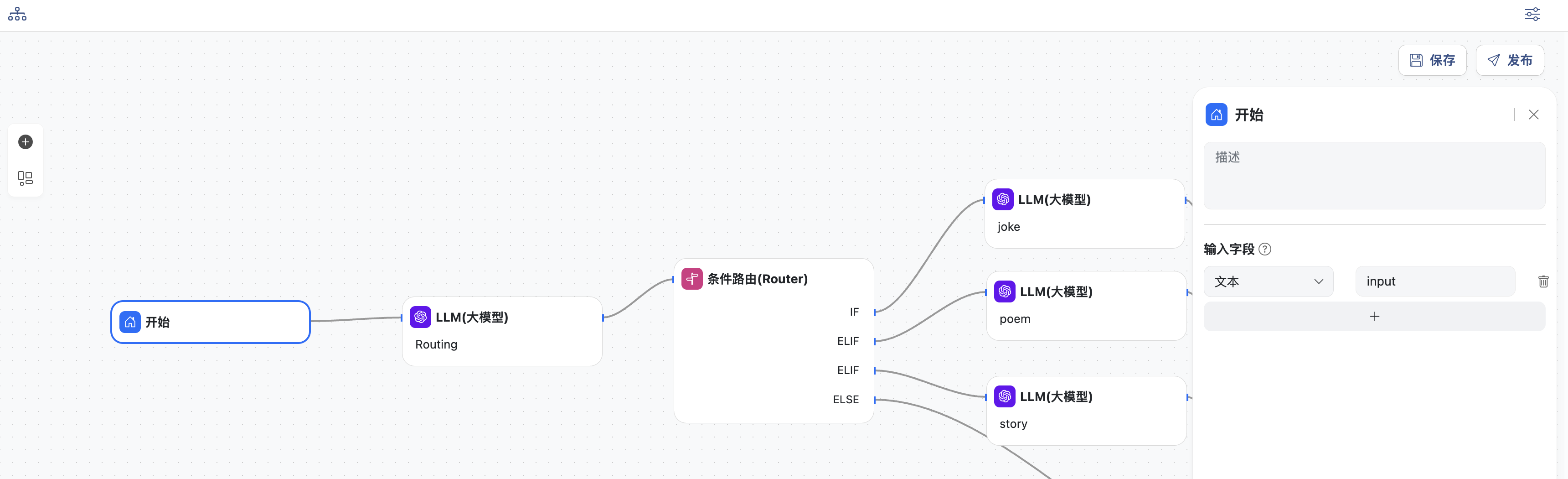
- LLM节点,根据输入的内容进行判断,将判断结果结构化输出
- 选择一个模型
- 输入系统提示词
- 用户输入直接使用上下文变量:
input - 定义模型结构化输出:输出的变量名为
decision,类型为枚举,值为:joke,poem,story
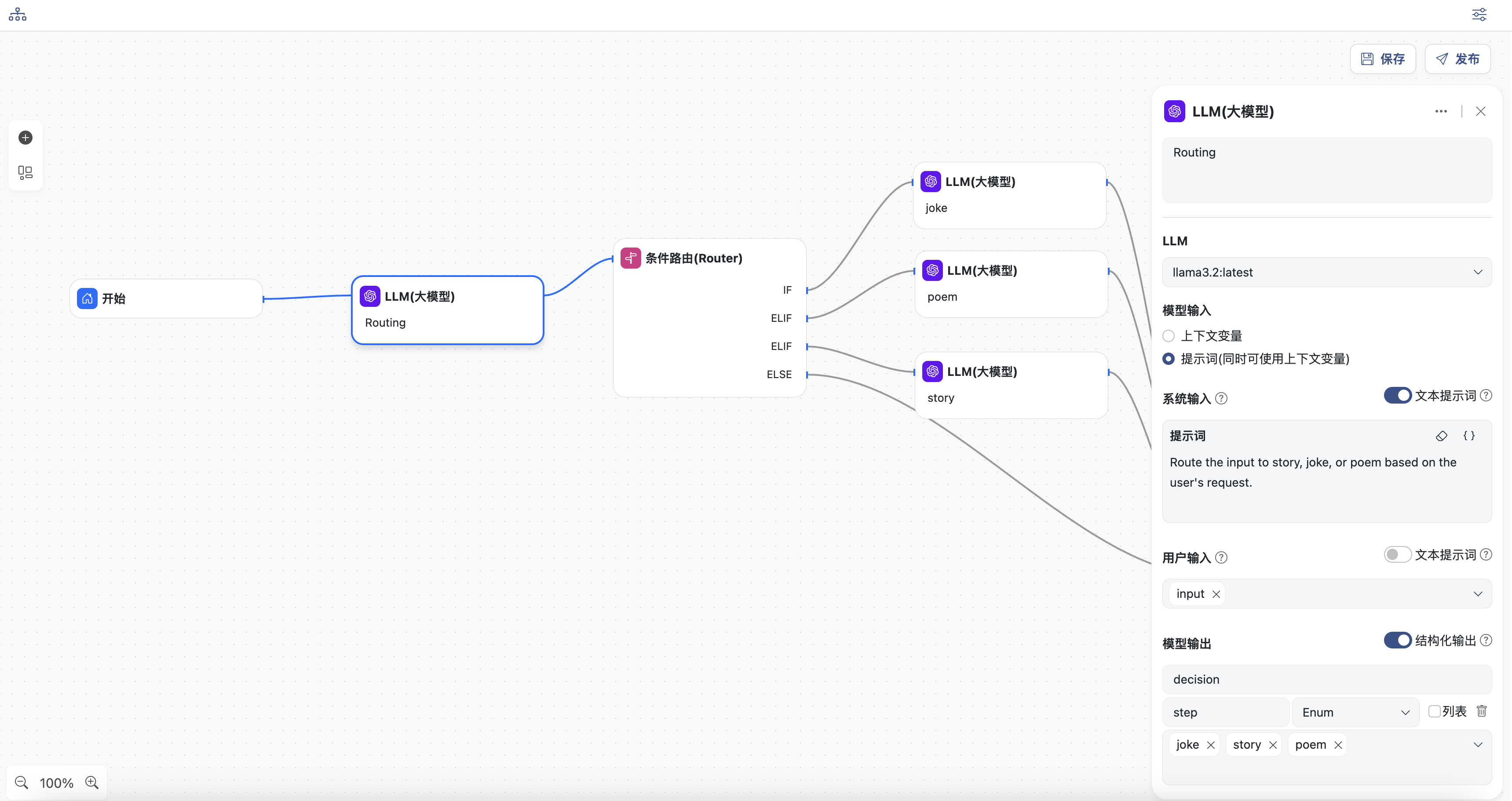
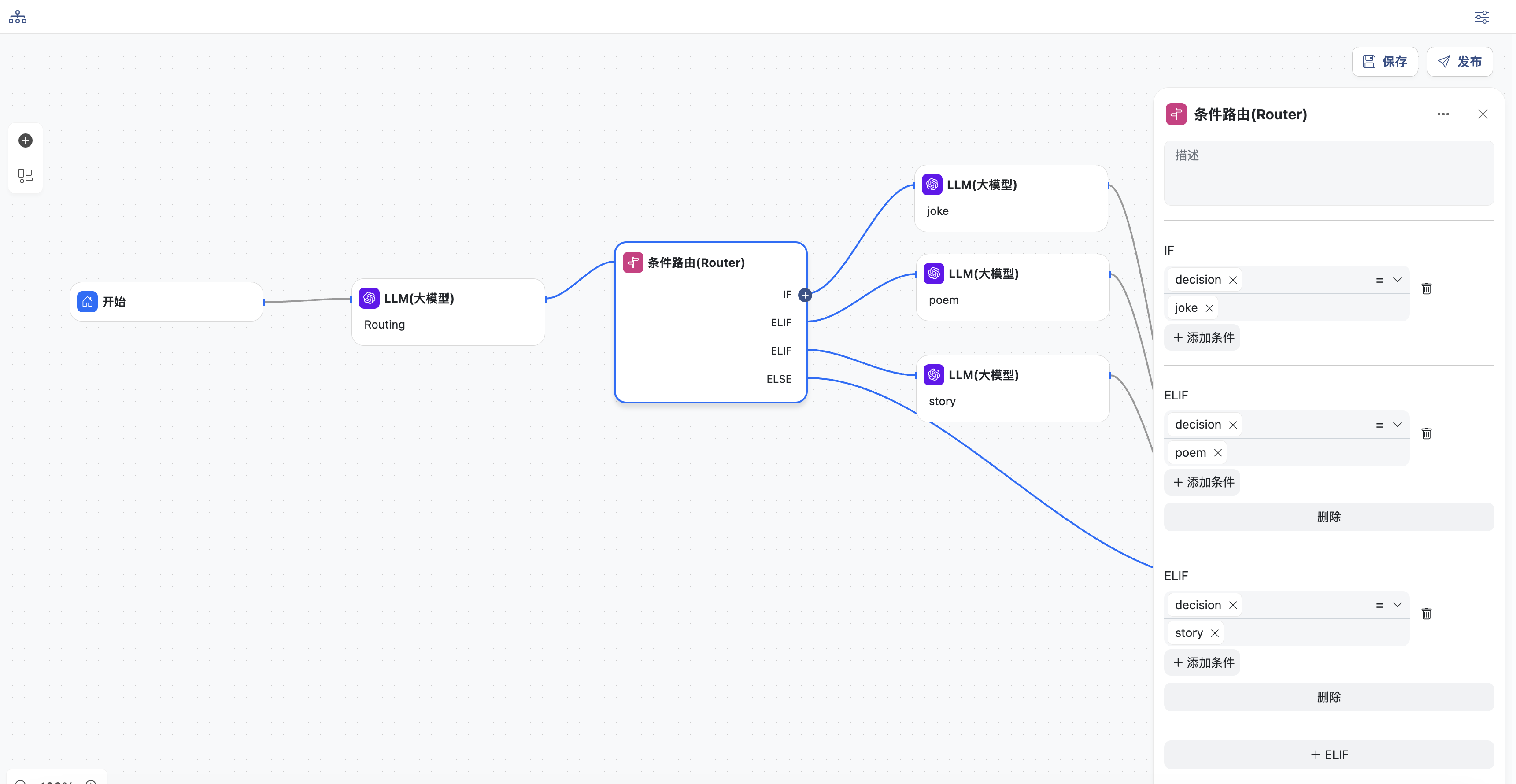
- 条件路由节点,添加3个IF或ELIF条件,分别为
decision=joke,decision=poem,decision=story
根据上一节点的识别结果,判断进入到哪一个后续节点
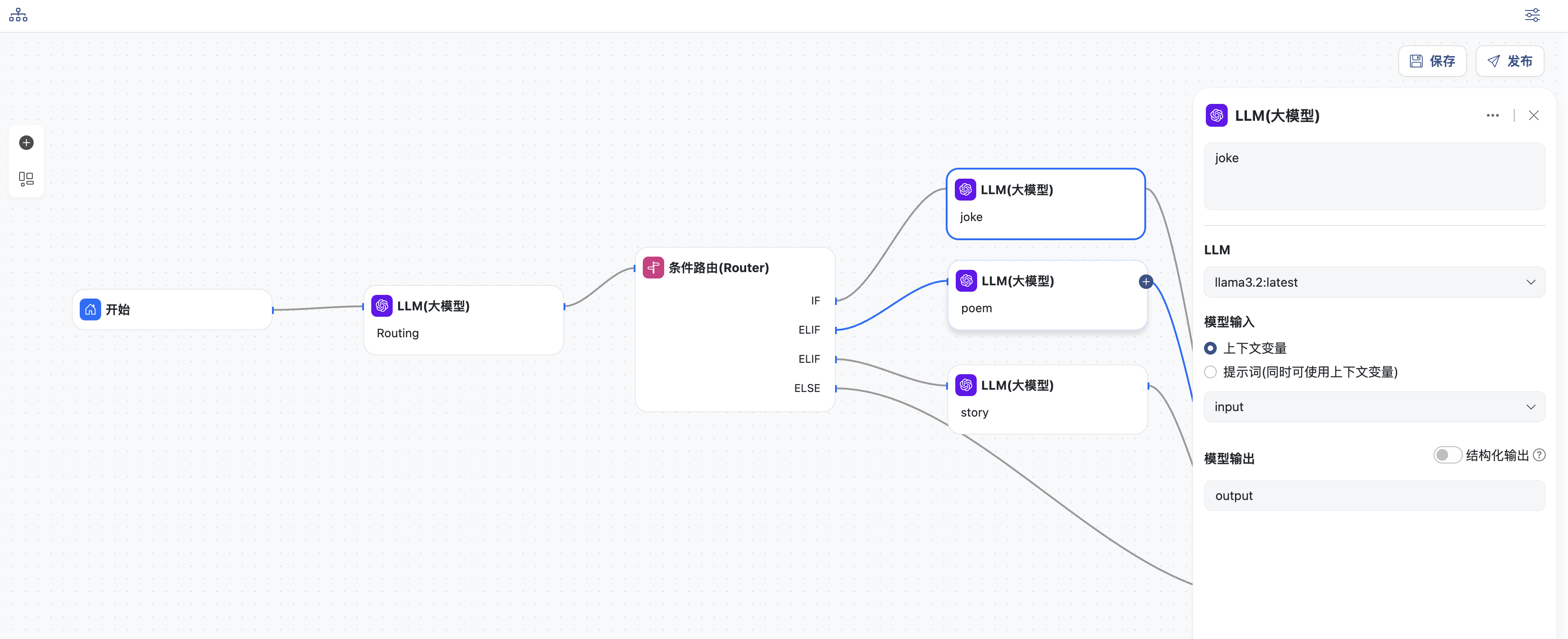
- 三个分支的LLM节点,分别生成笑话、诗歌和故事。分别配置各个节点:
- 选择一个模型
- 输入直接选择上下文变量:
input - 同时定义模型输出,变量名为:
output
- 结束节点,输出结果
- 直接输入结果变量:
output
协调工作模式
在协调工作流中,协调器 LLM 会动态分解任务,将其委托给工作 LLM,并合成其结果。
什么情况下使用此类型工作流程:此工作流非常适合无法预测所需子任务的复杂任务(例如,在编码过程中,需要更改的文件数量以及每个文件中更改的性质可能取决于任务本身)。
虽然两者在拓扑结构上相似,但其与并行化的主要区别在于灵活性——子任务并非预先定义,而是由协调器根据特定输入确定。
- 开始节点,定义工作流的主题,变量名为:
topic,这里是关于一份报告的主题
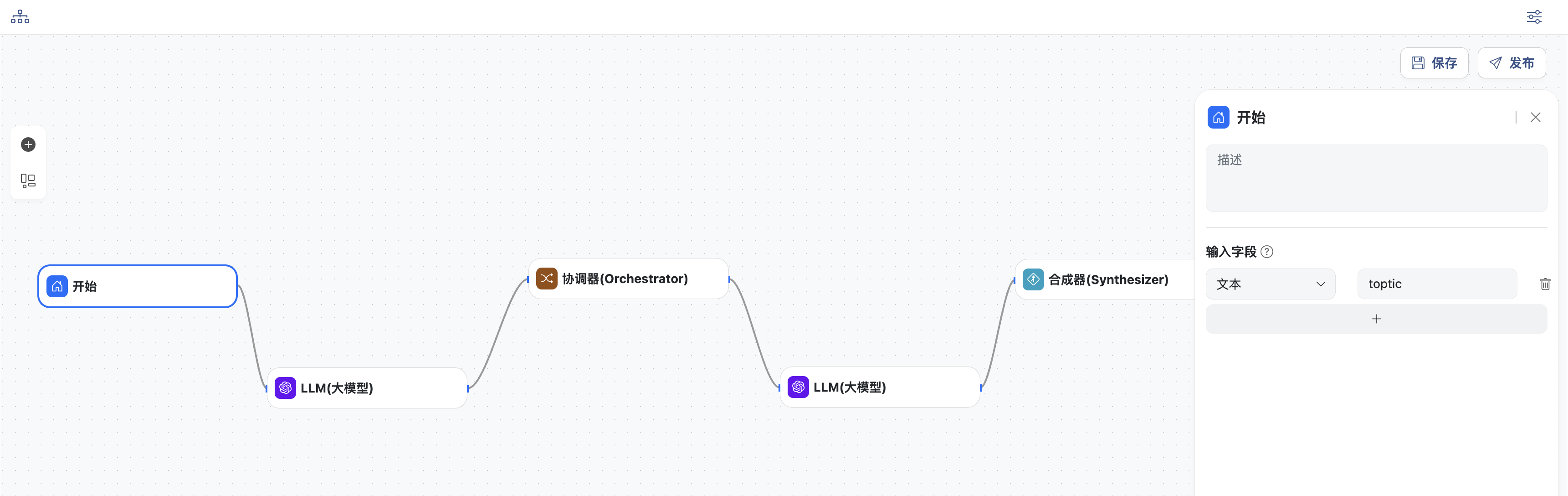
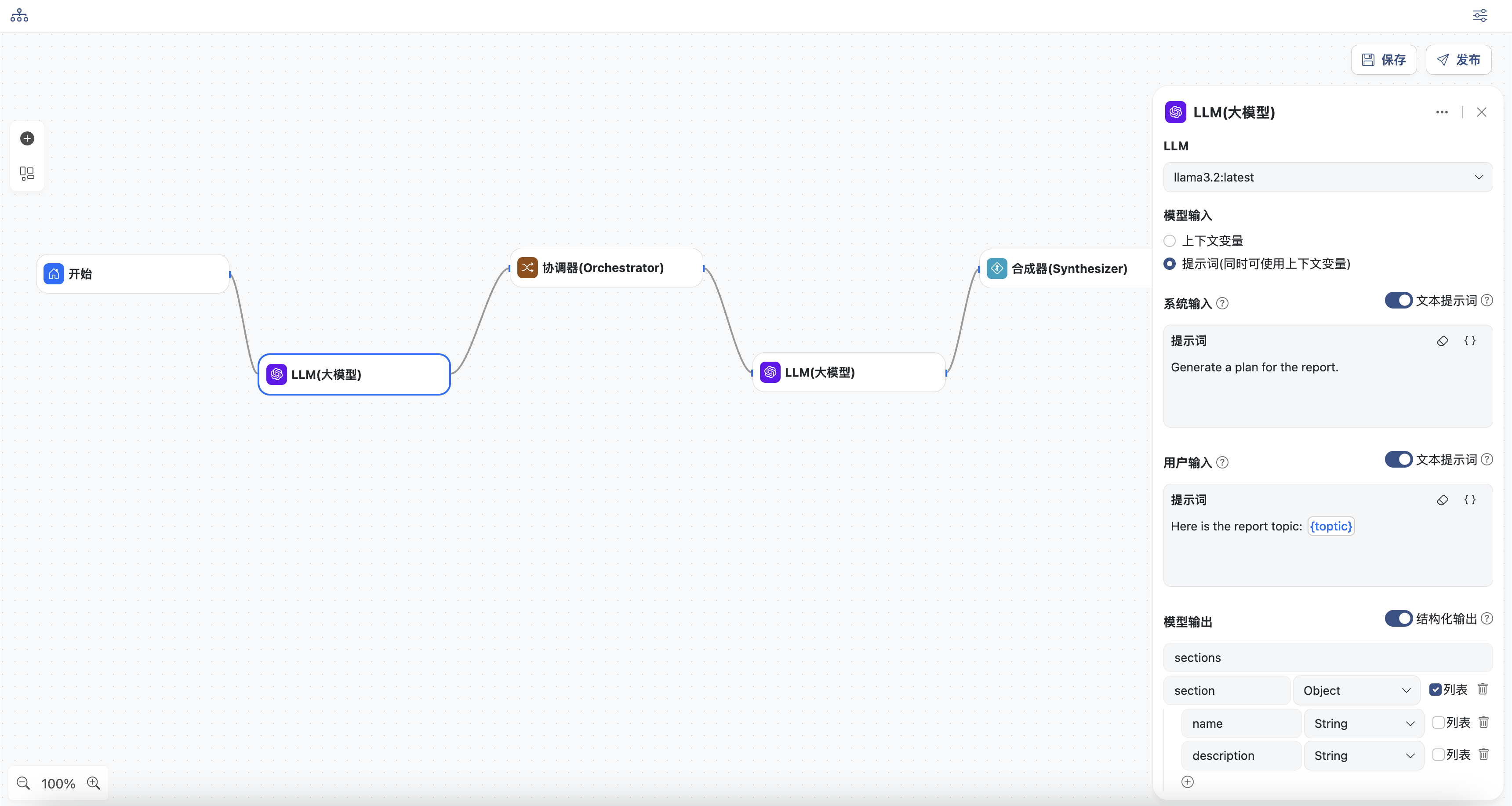
- LLM生成节点,生成报告并结构化输出
- 选择一个模型
- 输入系统提示词
- 输入用户提示词,可以选择上下文变量,这里选择
topic - 定义模型结构化输出:定义一个对象
section包含name和description字段,再定义一个对象sections,包含一个section的列表字段
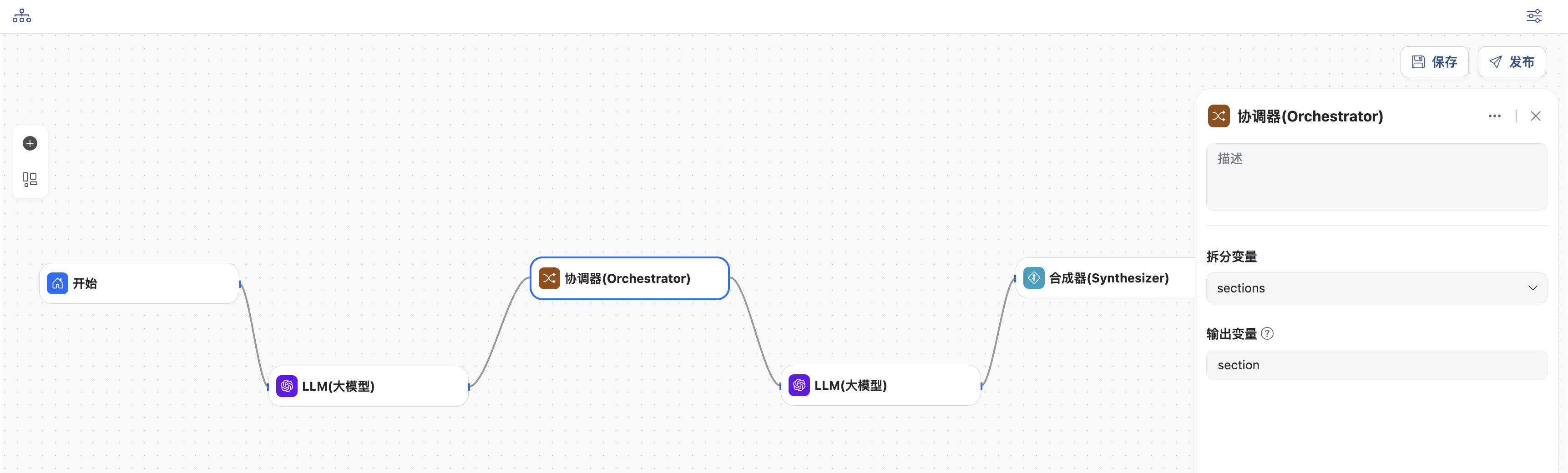
- 协调节点
- 拆分上一节点生成的变量:
sections - 定义输出变量:
section
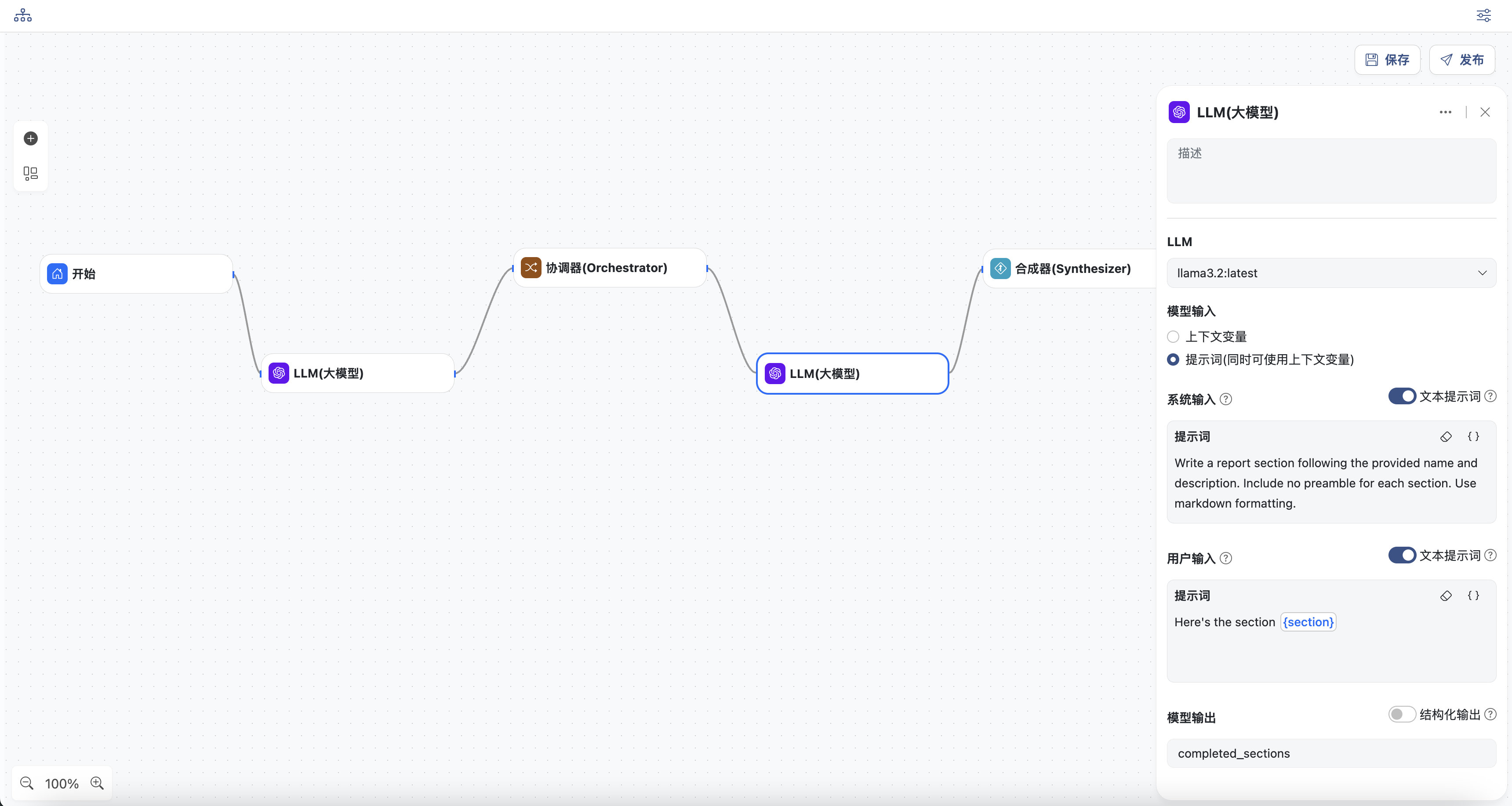
- LLM工作节点
- 选择一个模型
- 输入系统提示词
- 输入用户提示词,可以选择上下文中的变量,此处选择
section - 定义输出变量:
completed_section
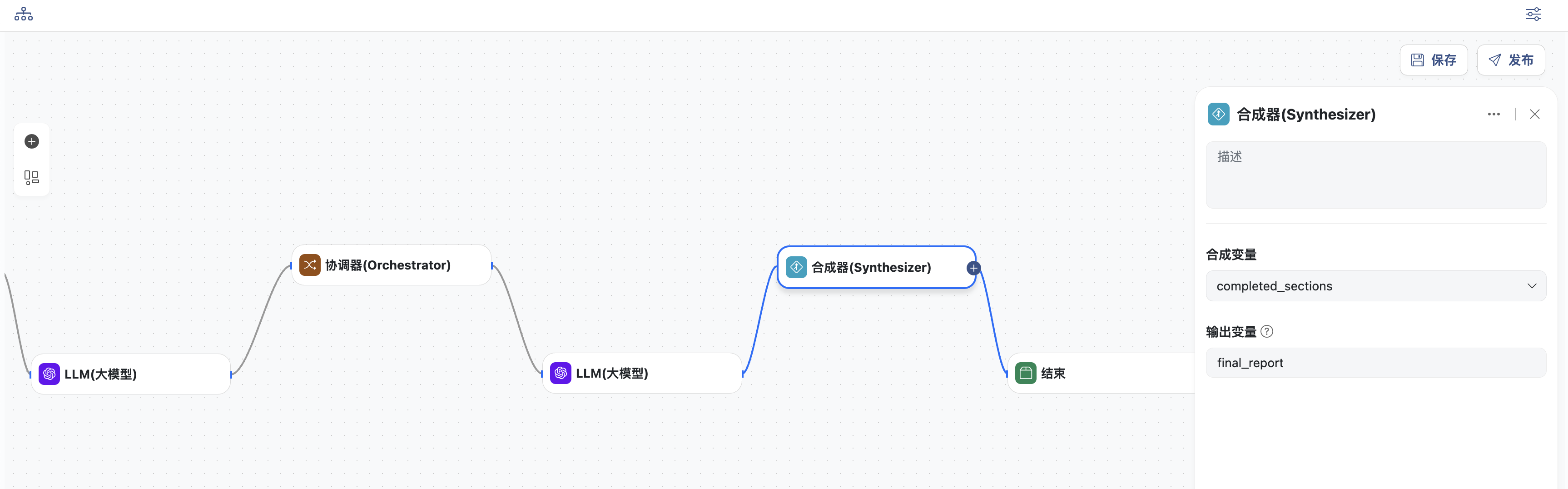
- 合成节点
- 选择需要合成的变量:
completed_section - 定义输出变量:
final_report
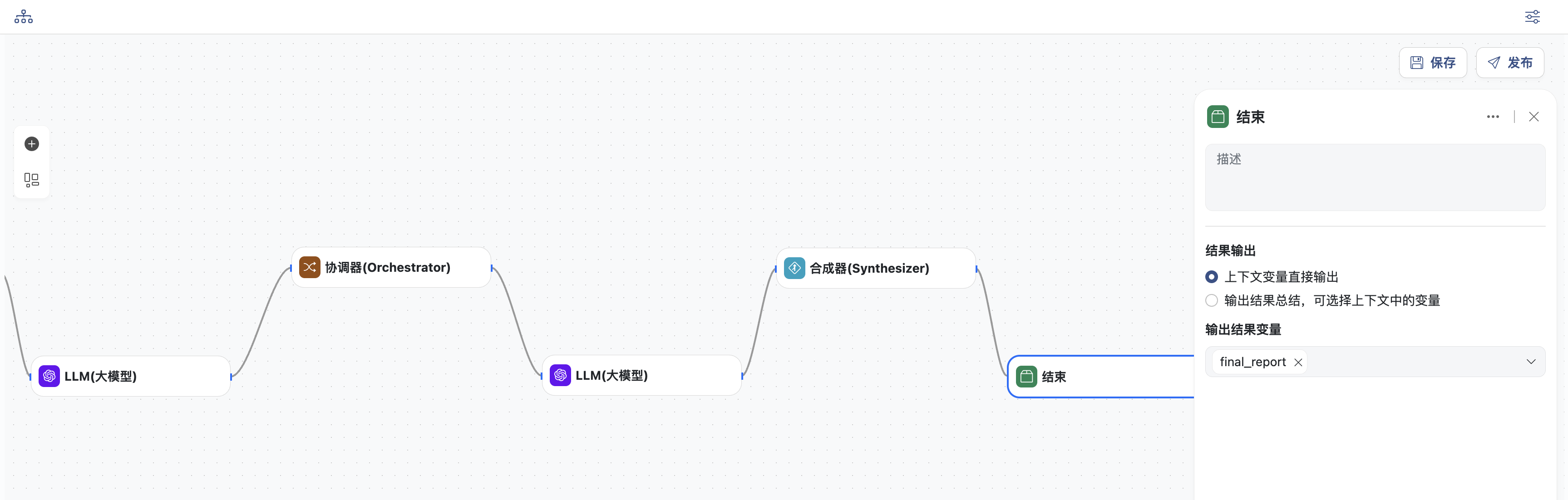
- 结束节点,输出结果
- 直接输入结果变量:
final_report
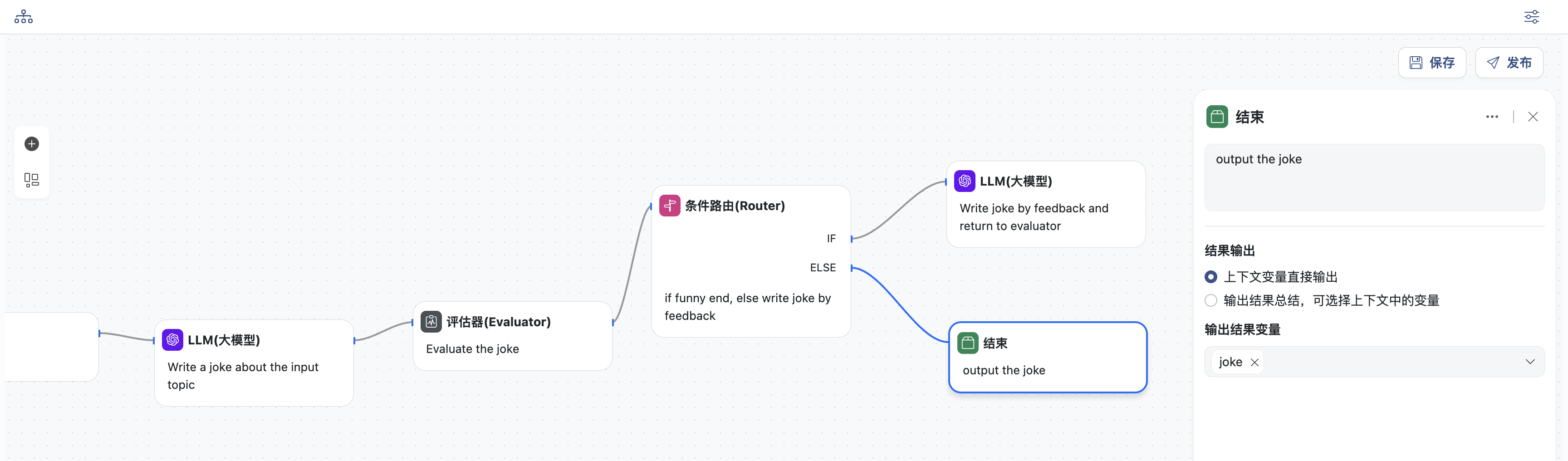
评估优化模式
在评估器-优化器工作流程中,一个 LLM 调用生成响应,另一个调用则循环提供评估和反馈。
什么情况下使用此类型工作流程:当我们拥有明确的评估标准,并且迭代改进能够提供可衡量的价值时,此工作流程尤其有效。
良好契合的两个标志是:
- 首先,当人类清晰地表达反馈时,LLM 响应可以得到显著改进;
- 其次,LLM 能够提供此类反馈。这类似于人类作家在撰写精良文档时可能经历的迭代写作过程。
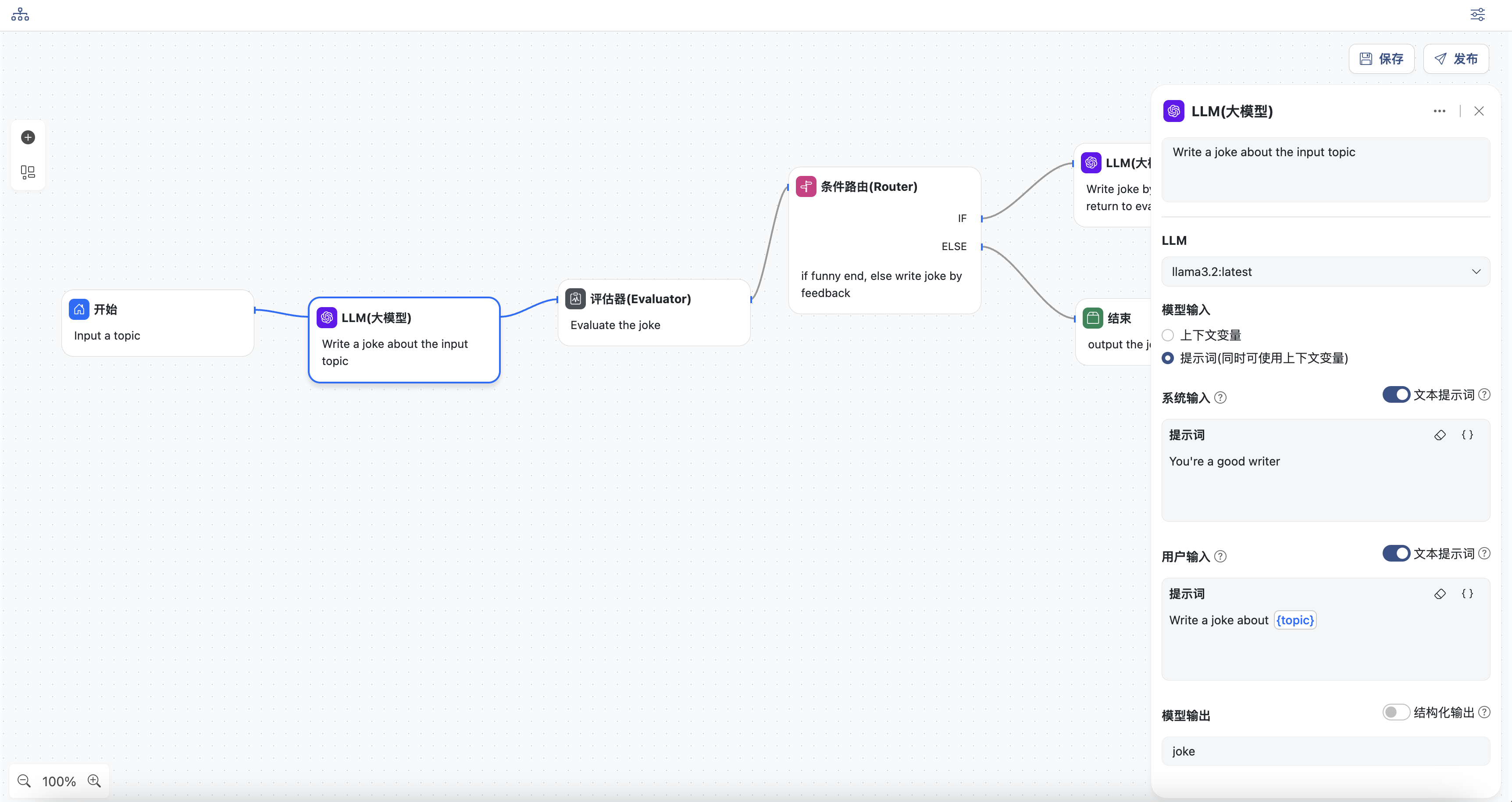
- 开始节点,定义工作流的主题,变量名为:
topic,这里是关于一则笑话的主题
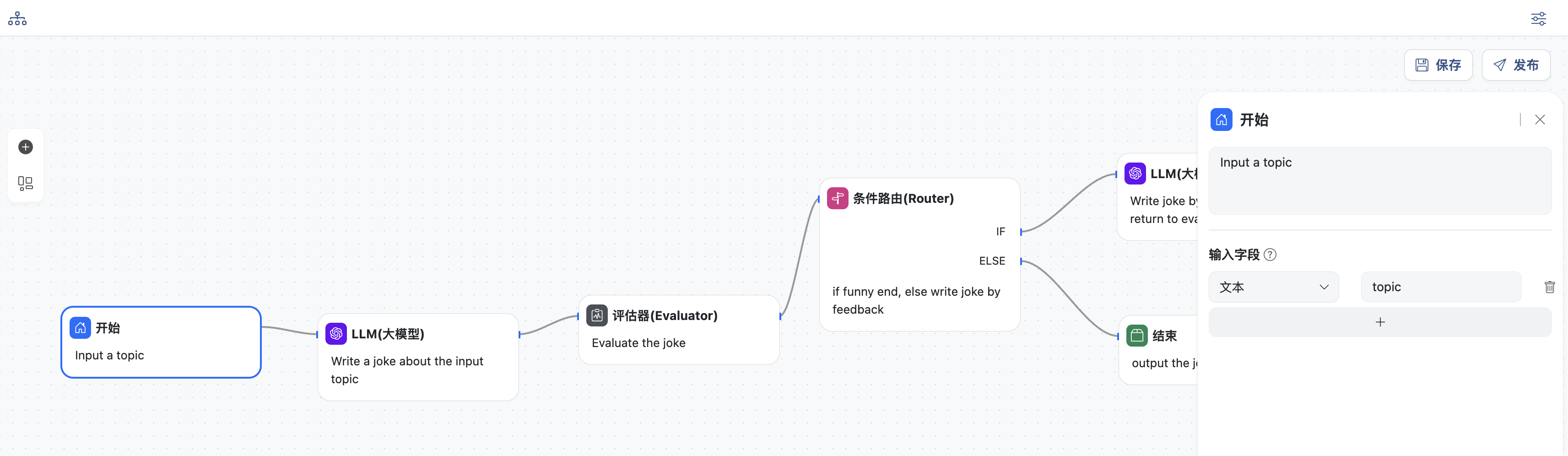
- LLM生成节点
- 选择一个模型
- 输入系统提示词
- 输入用户提示词,可以选择上下文中的变量,此处选择:
topic - 同时定义模型输出,变量名为:
joke
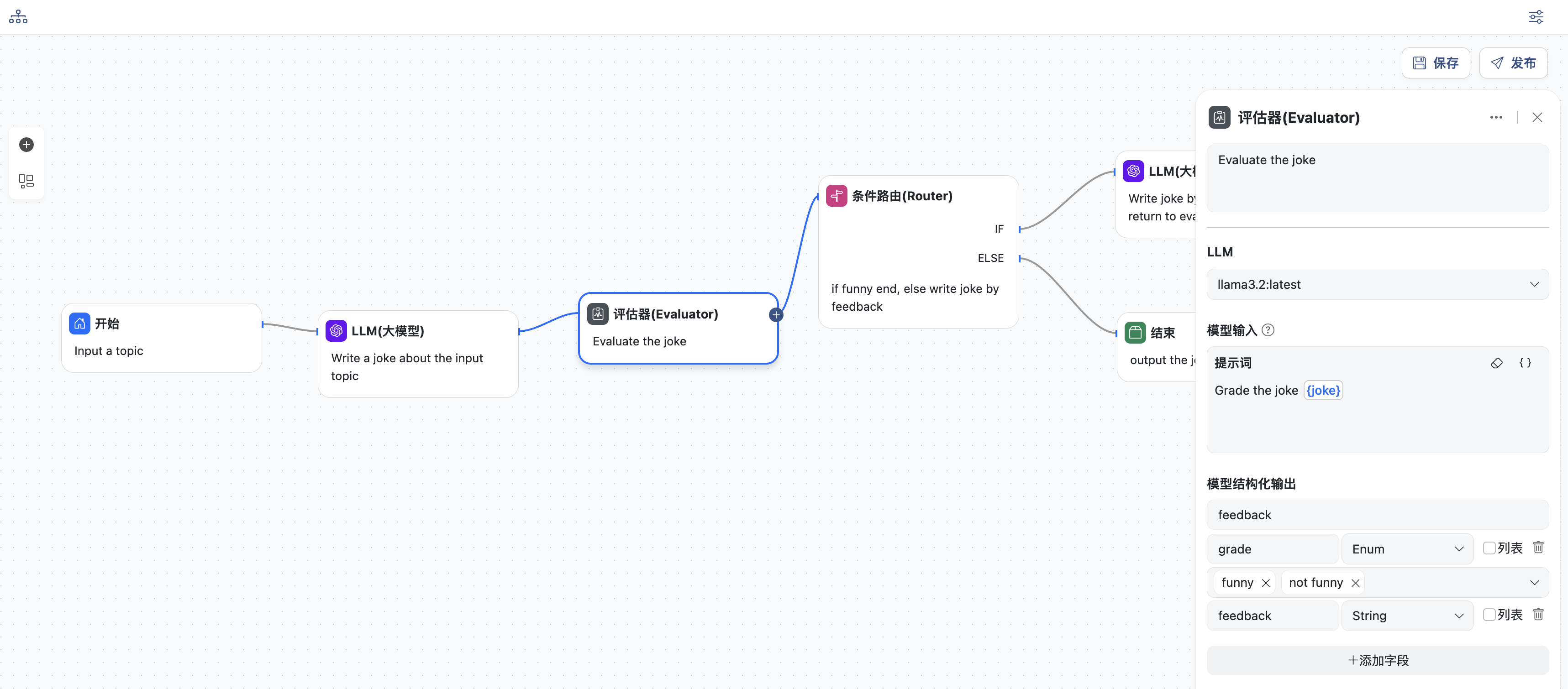
- 评估节点
- 选择一个模型
- 输入提示词,对生成内容进行评估,可以选择上下文中的变量,此处选择:
joke - 同时定义模型结构化输出:变量名为
feedback,内容为对象类型,包含两个字段grade和feedback
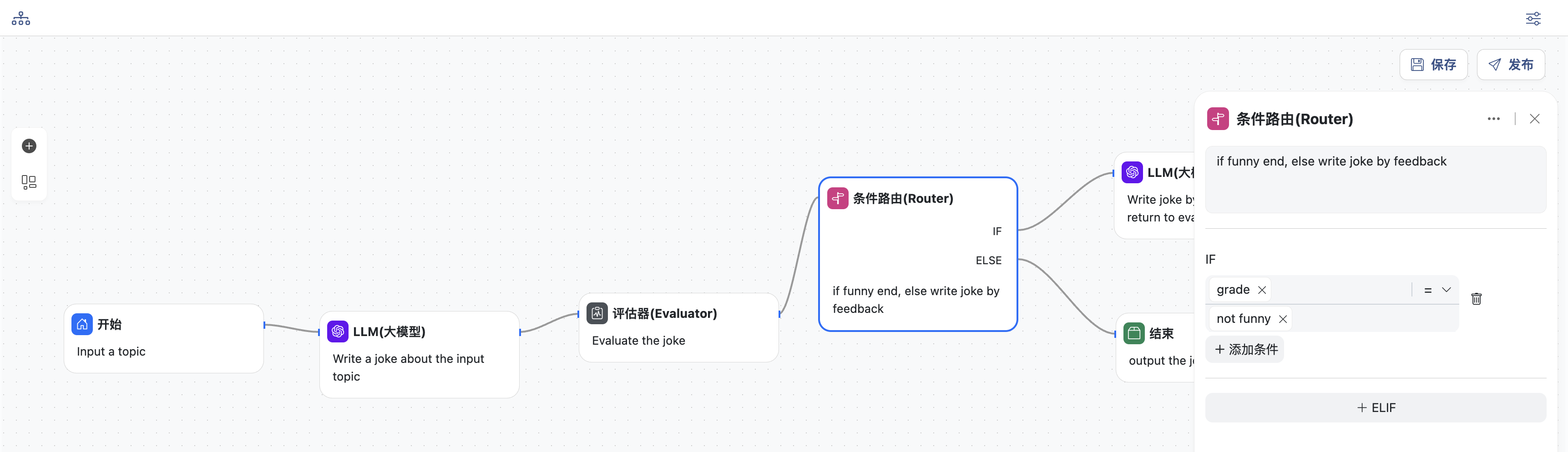
- 条件路由节点,添加一个IF条件
- 如果
grade = not funny,则进入重新生成节点 - 否则进入结束节点,直接退出
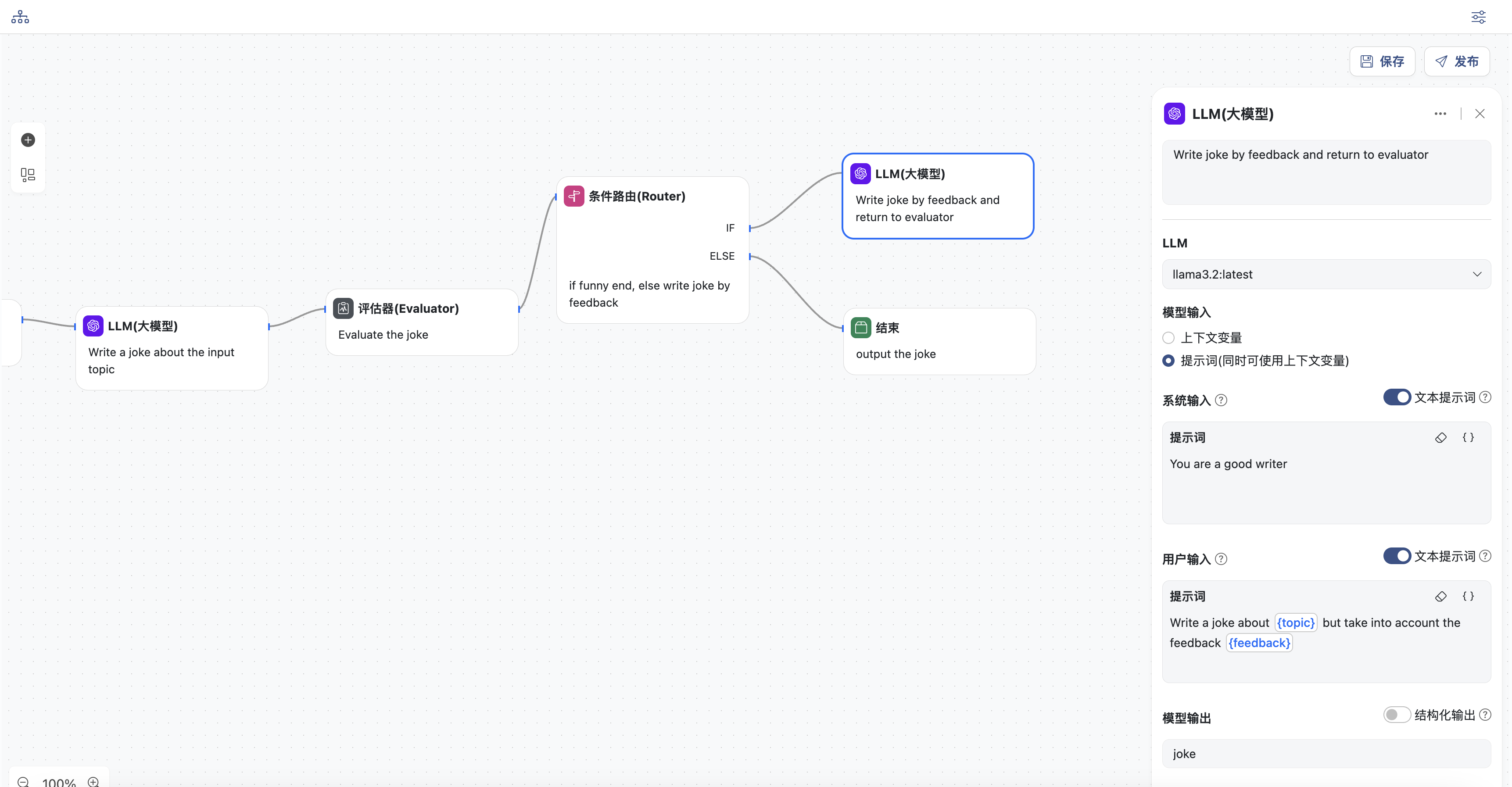
- LLM重新生成节点,生成之后会再次返回评估节点,进行评估
- 选择一个模型
- 输入系统提示词
- 输入用户提示词,要求根据评估反馈结果来重新生成, 可以选择上下文中的变量,此处选择:
topic和feedback - 同时定义模型输出,变量名为:
joke
- 结束节点,输出结果
- 直接输入结果变量:
joke